
После перенесения данных из программы Access на сервер SQL Server у вас появилась база данных клиента или сервера. База данных может быть локальной или представлять собой гибридное облачное решение Azure. В любом случае программа Access теперь обеспечивает презентацию данных, а SQL Server — их непосредственную обработку. Теперь самое время еще раз рассмотреть разные аспекты вашего решения, особенно производительность запросов, безопасность и непрерывность бизнес-процессов. Это позволит улучшить и масштабировать базу данных.
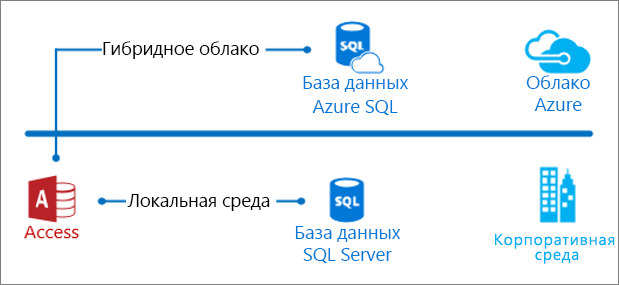
Сначала пользователям программы Access может быть нелегко работать с документацией SQL Server и Azure. Это руководство поможет вам ознакомиться с основными функциями. Это подготовит к дальнейшему исследованию достижений в области технологий баз данных.
В этой статье
|
Управление базами данных Непрерывность бизнес-процессов |
Запросы и связанные данные |
Типы данных |
Другое |
Непрерывность бизнес-процессов
Используя программу Access, вы стремитесь свести до минимума перебои в ее работе, но возможности внутренней базы данных в Access ограничены. Для защиты данных крайне важно создавать резервные копии базы данных Access, но для этого пользователь должен перейти в автономный режим. Кроме этого, случаются незапланированные простои из-за обновления оборудования или программного обеспечения, отказа сети или сбоя питания, неисправности оборудования, нарушения безопасности или даже кибератаки. Чтобы свести к минимуму простои и их последствия для бизнеса, можно создать резервную копию базы данных SQL Server прямо во время ее использования. Кроме того, в программе SQL Server также предусмотрены стратегии высокой доступности (HA) и аварийного восстановления (DR). Сочетание этих двух технологий называется HADR. Дополнительные сведения см. в статьях Непрерывность бизнес-процессов и восстановление базы данных и Непрерывность бизнес-процессов с SQL Server (электронная книга).
Резервное копирование во время использования базы данных
Программа SQL Server использует резервное копирование на базе веб-служб, которое проводится во время работы базы данных. Можно сделать полную, частичную резервную копию или резервную копию файла. Чтобы обеспечить полное восстановление, делают резервные копии данных и журналов транзакций. Особенно в случае локальной базы данных важно понимать различия между простой и полной моделью восстановления и то, как это влияет на размер журнала транзакций. Дополнительные сведения см. в статье Модели восстановления.
Большинство операций резервного копирования происходят сразу же, за исключением управления файлами и сжатия базы данных. С другой стороны, при попытке создать или удалить файл базы данных во время резервного копирования происходит сбой. Подробнее см. в статье Общие сведения о резервном копировании.
HADR
Два наиболее распространенных способа достижения высокой доступности и непрерывности бизнес-процессов — это зеркальное отражение и кластеризация. SQL Server интегрирует технологии зеркального отражения и кластеризации с помощью экземпляров отказоустойчивого кластера AlwaysOn и групп доступности AlwaysOn.
Зеркальное отображение обеспечивает на уровне базы данных почти мгновенную отработку отказа. Это возможно с помощью резервной базы данных, полной копии или зеркала активной базы данных на отдельном оборудовании. Сеанс может проходить в синхронном режиме (высокий уровень безопасности), когда входящая транзакция фиксируется на всех серверах одновременно, или в асинхронном (высокая производительность), когда входящая транзакция фиксируется в активной базе данных, а затем в определенной точке копируется в зеркало. Зеркальное отображение работает на уровне баз данных. Оно используется только для баз данных с полной моделью восстановления.
Кластеризация работает на уровне серверов. Она объединяет серверы в единое хранилище данных и воспринимается пользователями как один экземпляр. Пользователи подключаются к этому экземпляру, не беспокоясь о том, какой сервер сейчас активен. В случае отказа одного из серверов или его перевода в автономный режим для обслуживания, взаимодействие с пользователем не изменяется. Диспетчер кластеров контролирует каждый сервер в кластере с помощью пакетов пульса. Когда он обнаруживает, что активный сервер перешел в автономный режим, он оперативно переключается на следующий сервер в кластере. Переключение вызывает задержку разной длительности.
Дополнительные сведения см. в статьях Экземпляры отказоустойчивого кластера AlwaysOn и Группы доступности AlwaysOn: высокая доступность и аварийное восстановление.
Безопасность SQL Server
Хотя базу данных Access можно защитить с помощью центра управления безопасностью и шифрования базы данных, сервер SQL Server имеет дополнительные функции безопасности. Далее рассматриваются три возможности, которые открываются для пользователя программы Access. Дополнительные сведения см. в статье Обеспечение безопасности SQL Server.
Проверка подлинности базы данных
SQL Server использует четыре способа проверки подлинности базы данных, любой из которых можно указать в строке подключения ODBC. Дополнительные сведения см. в статье Ссылка на данные или импорт данных из базы данных SQL Server Azure. У каждого из этих способов есть свои преимущества.
Встроенная проверка подлинности Windows Используйте учетные данные Windows для проверки пользователей, создания ролей безопасности и ограничения доступа пользователей к функциям и данным. В программе можно воспользоваться учетными данными домена и легко управлять правами пользователей. При необходимости введите имена субъектов-служб (SPN). Дополнительные сведения см. в статье Выбор режима проверки подлинности.
Проверка подлинности SQL Server Пользователи подключаются с помощью учетных данных, заданных в базе данных. Для этого нужно ввести имя пользователя и пароль во время первого входа в базу данных за сеанс. Дополнительные сведения см. в статье Выбор режима проверки подлинности.
Встроенная проверка подлинности Azure Active Directory — подключение к базе данных Azure SQL Server с помощью Azure Active Directory. Если настроена проверка подлинности Azure Active Directory, вводить имя пользователя и пароль не нужно. Дополнительные сведения см. в статье Использование аутентификации Azure Active Directory для аутентификации с помощью базы данных SQL или хранилища данных SQL.
Проверка подлинности пароля Active Directory — подключение с помощью учетных данных, заданных в Azure Active Directory, путем ввода имени пользователя и пароля. Дополнительные сведения см. в статье Использование аутентификации Azure Active Directory для аутентификации с помощью базы данных SQL или хранилища данных SQL.
Совет Воспользуйтесь функцией обнаружения угроз, чтобы получать оповещения об аномальных действиях в базе данных, указывающих на потенциальную угрозу безопасности для базы данных SQL Server Azure. Дополнительные сведения см. в статье Обнаружение угроз безопасности базы данных SQL.
Безопасность приложений
SQL Server поддерживает две функции безопасности на уровне приложений, которыми можно воспользоваться в программе Access.
Динамическое маскирование данных Скройте конфиденциальные данные, маскируя их от непривилегированных пользователей. Например, можно частично или полностью скрыть номера социального страхования.
 Частичное маскирование данных |
 Полное маскирование данных |
Маску данных можно задать несколькими способами. Она применяется к разным типам данных. Маскирование данных выполняется на уровне таблицы и столбца для определенного набора пользователей и применяется к запросу в режиме реального времени. Дополнительные сведения см. в статье Динамическое маскирование данных.
Безопасность на уровне строк С помощью функции безопасности на уровне строк вы можете управлять доступом к определенным строкам базы, содержащим конфиденциальную информацию, на основе пользовательских характеристик. Эти ограничения доступа применяются к системе базы данных, благодаря чему система безопасности становится надежнее.

Существует два типа предикатов безопасности.
-
Предикат фильтра фильтрует строки из запроса. Фильтр прозрачный, и пользователь не подозревает о его использовании.
-
Предикат блокировки предотвращает несанкционированные действия и выбрасывает исключение, если действие не может быть выполнено.
Дополнительные сведения см. в статье Безопасность на уровне строк.
Защита данных с помощью шифрования
Защищайте данные при хранении, передаче и использовании, не снижая производительности базы данных. Дополнительные сведения см. в статье Шифрование SQL Server.
Шифрование данных при хранении Чтобы защитить личные данные, сохраненные на автономном носителе (уровень физического хранилища), воспользуйтесь функцией шифрования данных при хранении, которая также называется прозрачным шифрованием данных (TDE). Тогда ваши данные будут защищены даже в том случае, если физический носитель украден или неправильно уничтожен. Функция TDE выполняет шифровку и расшифровку баз данных, резервных копий и журналов транзакций в режиме реального времени, не внося каких-либо изменений в ваши приложения.
Шифрование данных при передаче Чтобы защитить данные, которые передаются по сети, от перехвата и атак через посредника, можно зашифровать их. SQL Server поддерживает протокол TLS 1.2 для обеспечения высокого уровня безопасности соединения. Протокол TDS также используется для защиты соединения в ненадежных сетях.
Шифрование данных для работы с клиентом Чтобы защитить личные данные во время работы, вам нужна функция Always Encrypted. Личные данные шифруются и расшифровываются драйвером на клиентском компьютере. Ключи шифрования для ядра СУБД не сообщаются. Поэтому зашифрованные данные отображаются только для тех, кто отвечает за управление данными, а не для других пользователей с привилегированными правами доступа, которым доступ не предоставлен. В зависимости от выбранного типа шифрования, функция Always Encrypted может ограничивать некоторые функции базы данных, такие как поиск, группирование и индексирование зашифрованных столбцов.
Соблюдение конфиденциальности
Проблемы с конфиденциальностью настолько распространены, что Европейский Союз определил соответствующие юридические требования в Общем регламенте по защите данных (GDPR). К счастью, серверная часть SQL Server удовлетворяет этим требованиям. Далее описаны три этапа реализации регламента GDPR.

Шаг 1. Оценка риска нарушения законодательства и управление этим риском
Регламент GDPR требует, чтобы были найдены личные данные, содержащиеся в таблицах и файлах, и велся их учет. Это могут быть любые из перечисленных ниже данных: имя, фотография, адрес электронной почты, банковские реквизиты, записи в социальных сетях, медицинская информация или даже IP-адрес.
Новый инструмент SQL Data Discovery and Classification, встроенный в SQL Server Management Studio, помогает находить, классифицировать, помечать конфиденциальные данные и сообщать о них, применяя два атрибута метаданных к столбцам.
-
Метки Определение степени конфиденциальности данных
-
Типы данных Дальнейшая детализация типов данных, хранящихся в столбце
Другой механизм обнаружения — это полнотекстовый поиск, при котором используются предикаты CONTAINS и FREETEXT и такие функции со значением набора строк, как CONTAINSTABLE и FREETEXTTABLE, а также инструкция SELECT. С помощью полнотекстового поиска можно искать в таблицах слова, сочетания слов, а также варианты слов, например синонимы или флективные формы. Дополнительные сведения см. в статьеПолнотекстовый поиск.
Шаг 2. Защита личных данных
Регламент GDPR требует защитить личные данные и ограничить доступ к ним. Помимо стандартных действий по управлению доступом к сети и ресурсам, например настройка параметров брандмауэра, можно использовать функции безопасности SQL Server, которые помогут вам управлять доступом к данным.
-
Проверка подлинности SQL Server, чтобы управлять удостоверением пользователя и предотвращать несанкционированный доступ.
-
Безопасность на уровне строк, чтобы ограничить доступ к строкам в таблице в зависимости от связи между пользователем и данными.
-
Динамическое маскирование данных, чтобы ограничить доступ к личным данным, скрыв их от непривилегированных пользователей.
-
Шифрование для защиты личных данных во время передачи и хранения и для защиты от компрометации, в том числе на стороне сервера.
Дополнительные сведения см. в статье Безопасность SQL Server.
Шаг 3. Оперативные ответы на запросы
Регламент GDPR требует, чтобы велись записи об обработке личных данных и чтобы они предоставлялись в органы надзора по требованию. Если возникли проблемы, связанные со случайным разглашением данных, элементы управления защитой позволяют быстро отреагировать на них. Если необходимо предоставить отчет, следует обеспечить быстрый доступ к данным. Например, регламент GDPR требует, чтобы органы надзора получили отчет о нарушении конфиденциальности данных “не позднее чем через 72 часа после того, как это было обнаружено”.
SQL Server 2017 облегчает вам создание отчетов несколькими способами.
-
SQL Server Audit обеспечивает наличие постоянных записей о доступе в базу данных и об обработке данных. Эта функция проводит детальный аудит и отслеживает деятельность в базе данных. Это помогает выявить потенциальные угрозы, предполагаемые нарушения и проблемы безопасности. Вы можете легко провести экспертизу данных.
-
Темпоральные таблицы SQL Server — это пользовательские таблицы с системным управлением версиями, которые позволяют сохранить всю историю изменений данных. Их можно использовать, чтобы легко создавать отчеты и проводить анализ на определенный момент времени.
-
SQL Vulnerability Assessment помогает выявить проблемы с безопасностью или разрешениями. При обнаружении проблемы вы также можете детализировать отчеты базы данных, чтобы найти решение проблемы.
Дополнительные сведения см. в публикациях Создание платформы доверия (электронная книга) и Выполнение регламента GDPR.
Создание моментальных снимков базы данных
Моментальный снимок базы данных — это статическое представление базы данных SQL Server в определенный момент времени, доступное только для чтения. Хотя можно скопировать файл базы данных Access, чтобы оперативно создать моментальный снимок базы данных, в Access не встроена такая технология, как в SQL Server. Моментальный снимок базы данных используется для подготовки отчетов, основанных на данных на момент создания моментального снимка. Кроме того, моментальный снимок базы данных можно использовать для сохранения исторических данных, например за каждый финансовый квартал, для сведения отчетов за отчетный период. Советуем следовать таким рекомендациям:
-
Присвоение имени моментальному снимку Для каждого моментального снимка требуется уникальное имя в базе данных. Чтобы облегчить идентификацию, добавьте к имени назначение и временные рамки. Например, создайте три моментальных снимка базы данных AdventureWorks за день с 06:00 до 18:00 (24-часовой формат времени) с интервалом 6 часов и присвойте им такие имена: AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200 и AdventureWorks_snapshot_1800.
-
Ограничение количества моментальных снимков Каждый снимок базы данных сохраняется до тех пор, пока не будет полностью удален. Так как каждый следующий моментальный снимок будет увеличиваться, может потребоваться сэкономить место на диске, удалив более старый снимок после создания нового. Например, если вы создаете ежедневные отчеты, храните моментальные снимки в течение 24 часов, а затем удаляйте их и заменяйте новыми.
-
Подключение к необходимому моментальному снимку Чтобы использовать моментальный снимок базы данных, внешний интерфейс Access должен знать правильное расположение. Чтобы заменить имеющийся моментальный снимок новым, необходимо перенаправить Access к новому снимку. Чтобы подключиться к нужному моментальному снимку базы данных, добавьте логику во внешний интерфейс Access.
Вот каким образом можно создать моментальный снимок базы данных.
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Доп. сведения смотрите в статье Мгновенные снимки базы данных (SQL Server).
Управление параллелизмом
Когда несколько человек одновременно пытаются изменить данные в базе данных, необходима система управления, чтобы изменения, вносимые одним пользователем, не влияли негативно на изменения, сделанные другим пользователем. Это называется управлением параллелизмом. Имеются две основные стратегии блокировки: пессимистическая блокировка и оптимистическая блокировка. Блокировка не позволяет пользователям изменять данные так, чтобы это влияло на других пользователей. Блокировка также обеспечивает целостность базы данных, особенно в запросах. В противном случае результаты могут быть неожиданными. Между тем, каким образом базы данных Access и SQL Server реализуют эти стратегии управления параллелизмом, есть важные отличия.
В программе Access стратегия блокировки по умолчанию оптимистическая и дает право на блокировку первому пользователю, который делает запись. В Access отображается диалоговое окно Конфликт записи для другого пользователя, старающегося сделать ту же запись в то же время. Чтобы разрешить конфликт, другой пользователь может сохранить запись, скопировать ее в буфер обмена или удалить изменения.
Чтобы изменить стратегию управления параллелизмом, можно также воспользоваться свойствомRecordLocks. Это свойство влияет на формы, отчеты и запросы и имеет три параметра.
-
Блокировки отсутствуют В форме, если пользователи одновременно редактируют одну и ту же запись, появляется диалоговое окно Конфликт записи. В отчете записи не блокируются во время просмотра или печати. В запросе записи не блокируются во время его выполнения. Так применяется оптимистическая блокировка в программе Access.
-
Все записи Все записи в базовой таблице или запросе блокируются, если форма открыта в представлении формы или режиме таблицы, когда просматривается или печатается отчет либо выполняется запрос. Пользователи могут читать записи во время блокировки.
-
Изменяемая запись (Только для форм и запросов.) Страница записей блокируется, как только пользователь начинает изменять любое поле записи, и остается заблокированной, пока он не перейдет к другой записи. В результате каждый раз запись может редактировать только один пользователь. Так применяется пессимистическая блокировка в программе Access.
Дополнительные сведения см. в статьях Диалоговое окно “Конфликт записи” и Свойство RecordLocks.
В SQL Server управление параллелизмом выполняется следующим образом:
-
Пессимистический После того как пользователь выполнит действие, вызывающее блокировку, другие пользователи не могут выполнять действия, конфликтующие с блокировкой, пока первый пользователь не снимет ее. Такое управление параллелизмом в основном применяется в средах с высокой конкуренцией за использование данных.
-
Оптимистический При оптимистическом параллелизме пользователи не блокируют данные во время чтения. Когда пользователь обновляет данные, система проверяет, не изменил ли их другой пользователь после прочтения. Если другой пользователь обновил данные, отображается ошибка. Увидев ошибку, пользователь обычно откатывает транзакцию и начинает заново. Такое управление параллелизмом в основном применяется в средах с низкой конкуренцией за использование данных.
Чтобы задать тип управления параллелизмом, выберите несколько уровней изоляции транзакции с помощью инструкции SET TRANSACTION. Они определяют уровень защиты транзакции от изменений, сделанных другими транзакциями.
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Уровень изоляции |
Описание |
|
Чтение незафиксированных данных |
Транзакции изолированы ровно настолько, чтобы не допустить чтения физически поврежденных данных. |
|
Чтение фиксированных данных |
Транзакции считывают данные, не ожидая, пока другая транзакция завершит считывание этих данных. |
|
Чтение с повтором |
Чтение и запись выбранных данных блокируются до конца транзакции, но возможно чтение фантомов. |
|
Моментальный снимок |
Чтобы обеспечить согласованность чтения на уровне транзакции, используется версия строки. |
|
Сериализуемость |
Транзакции полностью изолированы друг от друга. |
Дополнительные сведения см. в статье Руководство по блокированию транзакций и управлению версиями строк.
Улучшение производительности запросов
После того как вы работали с запросом к серверу Access, воспользуйтесь прогрессивными средствами SQL Server для более эффективной работы.
В отличие от базы данных Access, SQL Server инициирует параллельные запросы, чтобы оптимизировать выполнение запросов и индексировать операции для компьютеров, на которых установлено несколько микропроцессоров (ЦП). Так как SQL Server может параллельно выполнять запросы и индексировать операции с помощью нескольких системных рабочих потоков, это выполняется быстро и эффективно.
Запросы — это критически важный компонент для повышения общей производительности базы данных. Неправильные запросы выполняются, пока не истечет время ожидания, они расходуют такие ресурсы, как ЦП и память, и действуют, как бандит в сети. Это мешает доступу к критически важной бизнес-информации. Даже один неправильный запрос может вызвать серьезные проблемы с производительностью базы данных.
Дополнительные сведения см. в статье Быстрое выполнение запросов с SQL Server (электронная книга).
Оптимизация запросов
Чтобы проанализировать производительность запроса и улучшить ее, необходимо сразу несколько инструментов: оптимизатор запросов, планы выполнения и хранилище запросов.
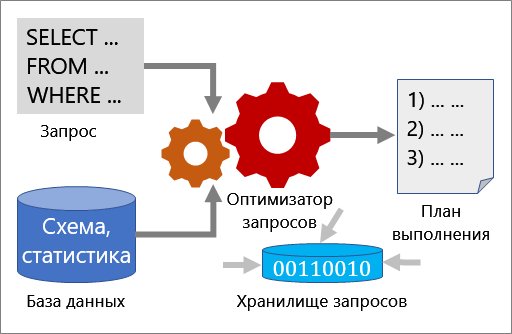
Оптимизатор запросов
Оптимизатор запросов — один из наиболее важных компонентов SQL Server. Используйте оптимизатор запросов, чтобы проанализировать запрос и определить наиболее эффективный способ доступа к необходимым данным. Входные данные для оптимизатора запросов включают запрос, схему базы данных (определение таблиц и индексов) и статистику базы данных. План выполнения — это результат работы оптимизатора запросов.
Дополнительные сведения см. в статье Оптимизатор запросов SQL Server.
План выполнения
План выполнения определяет последовательность доступа к исходным таблицам и то, какие методы использовать для извлечения данных из каждой таблицы. Оптимизация — это процесс выбора одного плана выполнения из многих потенциально возможных планов. У каждого из возможных планов выполнения есть сопутствующие затраты в размере стоимости использованных вычислительных ресурсов. Оптимизатор запросов выбирает план с наименьшей оценочной стоимостью.
База данных SQL Server также должна динамически настраиваться с учетом изменяющихся условий. Регрессия в планах выполнения запросов может сильно повлиять на производительность. Изменения, внесенные в базу данных, делают план выполнения неэффективным или недействительным с учетом нового состояния базы данных. SQL Server обнаруживает изменения, которые делают план выполнения недействительным, и помечает план соответствующим образом.
После этого необходимо составить новый план для следующего подключения, которое выполнит запрос. Требования, которые делают план недействительным:
-
изменения, внесенные в таблицу или представление, на которые ссылается запрос (ALTER TABLE и ALTER VIEW);
-
изменения, внесенные в индексы, используемые планом выполнения;
-
обновление статистики, используемой планом выполнения, автоматическое или в ответ на инструкцию UPDATE STATISTICS.
Подробнее см. в статье Планы выполнения.
Хранилище запросов
Хранилище запросов дает представление о выборе плана выполнения и производительности. Это упрощает решение проблем с производительностью, помогая быстро находить различия в производительности, вызванные изменениями в плане выполнения. Хранилище запросов собирает данные телеметрии, такие как журнал запросов, планы, статистику выполнения и статистику ожидания. Чтобы реализовать хранилище запросов, используйте инструкцию ALTER DATABASE.
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Дополнительные сведения см. в статье “Мониторинг производительности с помощью хранилища запросов”.
Автоматическое исправление плана
Возможно, что самый простой способ улучшить производительность запроса — это автоматическое исправление плана (функция доступна в базе данных SQL Azure). Просто включите эту функцию. Она постоянно проводит мониторинг и анализ плана выполнения, обнаруживает проблемные планы выполнения и автоматически исправляет проблемы с производительностью. Функция автоматического исправления плана использует стратегию, состоящую из четырех этапов (изучение, адаптация, проверка и повторение).
Дополнительные сведения см. в статье Автоматическая настройка.
Адаптивная обработка запросов
Кроме того, запросы выполняются быстрее, если просто обновить программу до версии SQL Server 2017, в которой используется новая функция адаптивной обработки запросов. SQL Server выбирает варианты плана запросов с учетом характеристик среды выполнения.
Оценка количества строк показывает, сколько приблизительно строк обрабатывается на каждом этапе плана выполнения. Неточная оценка может привести к длительному времени ответа на запрос, использованию ресурсов (памяти, ЦП и операции ввода-вывода) без необходимости и снижению пропускной способности и количества параллельных подключений. Чтобы адаптироваться к характеристикам рабочей нагрузки приложений, имеется три способа.
-
Пакетный режим результатов выполнения запросов во временно предоставленных буферах памяти Неправильная оценка количества строк может вызвать сбрасывание запросов на диск или усиленное заполнение памяти. SQL Server 2017 настраивает временно предоставленные буферы памяти в зависимости от количества результатов выполнения запросов и оптимизирует параллелизм для повторных запросов.
-
Пакетный режим для адаптивных соединений В зависимости от фактического количества строк ввода адаптивные соединения во время выполнения запросов динамически выбирают более подходящий тип внутреннего соединения (соединения с вложенными циклами, соединения слиянием, хэш-соединения). Поэтому во время выполнения запросов план может динамически переключаться на более подходящие соединения.
-
Попеременное выполнение Функции с табличным значением и несколькими инструкциями традиционно рассматриваются как черный ящик, когда речь идет об обработке запросов. SQL Server 2017 может лучше оценить количество строк, и это улучшает нисходящие операции.
Если включить для базы данных уровень совместимости 140, рабочая нагрузка автоматически станет пригодной для адаптивной обработки данных.
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Дополнительные сведения см. в статье Интеллектуальная обработка запросов в базах данных SQL.
Методы запросов
На сервере SQL Server предусмотрено несколько способов выполнения запросов, и каждый из них имеет свои преимущества. Важно узнать о них больше. чтобы выбрать подходящий вариант для Access. Самый лучший способ создавать запросы TSQL — это интерактивно редактировать и тестировать их с помощью редактора Transact-SQL в SQL Server Management Studio (SSMS). Этот редактор имеет функцию IntelliSense, которая помогает правильно выбирать ключевые слова и осуществлять проверку на наличие синтаксических ошибок.
Представления
В SQL Server представление похоже на виртуальную таблицу, данные которой берутся из одной или нескольких таблиц или других представлений. Но в запросах ссылки на представления такие же, как на таблицы. Представления позволяют скрыть сложность запросов и защитить данные путем ограничения набора строк и столбцов. Вот пример простого представления.
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Чтобы добиться оптимальной производительности и редактировать результаты представления, создайте индексированное представление. Оно хранится в базе данных так же, как таблицы, имеет свое дисковое пространство, и его можно запрашивать так же, как любую таблицу. Чтобы использовать его в Access, подключитесь к нему так же, как к таблице. Вот пример индексированного представления.
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Однако имеются ограничения. Если используется несколько базовых таблиц или представление содержит агрегатные функции или предложение DISTINCT, данные не обновляются. Если SQL Server возвращает сообщение об ошибке, так как не знает, какую запись нужно удалить, может потребоваться добавить в представление триггер удаления. Кроме того, в отличие от программы Access для запросов не используется предложение ORDER BY.
Дополнительные сведения см. в статьях Представления и Создание индексированных представлений.
Хранимые процедуры
Хранимая процедура — это группа из одной или нескольких инструкций TSQL, которые принимают входные параметры, возвращают выходные параметры и указывают на успех или отказ с помощью значения состояния. Они служат промежуточным уровнем между внешним интерфейсом Access и серверной частью SQL Server. Хранимые процедуры могут быть простыми, как инструкция SELECT, или сложными, как любое приложение. Вот пример.
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Если хранимая процедура используется в Access, она обычно возвращает результат в виде формы или отчета. Но она может выполнять и другие действия, которые не возвращают результаты, например инструкции DDL и DML. При использовании проходного запроса убедитесь, что вы правильно установили свойство Returns Records.
Дополнительные сведения см. в статье Хранимые процедуры.
Обобщенные табличные выражения
Обобщенные табличные выражения (CTE) похожи на временную таблицу, в которой создается результирующий именованный набор. Такое выражение используется для выполнения только одного запроса или инструкции DML. Выражение CTE встроено в ту же строку кода, что и инструкция SELECT или DML, в которой оно используется, тогда как создание и использование временной таблицы или представления обычно выполняется в два этапа. Вот пример.
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Выражение CTE имеет несколько указанных ниже преимуществ.
-
Так как выражения CTE являются временными, не нужно создавать их как постоянные объекты базы данных, такие как представления.
-
В запросе или инструкции DML можно ссылаться на одно и то же выражение CTE несколько раз. Это упрощает управление кодом.
-
Чтобы определить курсор, можно использовать запросы с ссылкой на выражение CTE.
Дополнительные сведения см. в статье WITH common_table_expression.
Пользовательские функции
Пользовательские функции (UDF) могут выполнять запросы и вычисления и возвращать либо скалярные значения, либо результирующие наборы данных. Они похожи на функции в языках программирования, которые принимают параметры, выполняют действие, например сложные вычисления, и возвращают результат действия в виде значения. Вот пример.
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Функция UDF имеет определенные ограничения. Например, она не может использовать некоторые недетерминированные системные функции, выполнять инструкции DML и DDL или динамические запросы SQL.
Дополнительные сведения см. в статье Пользовательские функции.
Добавление ключей и индексов
В любой системе баз данных есть ключи и индексы.
Ключи
В SQL Server необходимо создать первичные ключи для каждой таблицы и внешние ключи для каждой связанной таблицы. В SQL Server имеется функция, аналогичная функции типа данных для поля счетчика в Access. Это свойство Identity, которое используется для создания значений ключей. Если применить это свойство к какому-либо числовому столбцу, он становится доступным только для чтения и сохраняется системой баз данных. Если вставить запись в таблицу, содержащую столбец идентификаторов, система автоматически увеличит значение столбца на 1 и начиная с 1, но этими значениями можно управлять с помощью аргументов.
Дополнительные сведения см. в статье Свойство CREATE TABLE, IDENTITY.
Индексы
Как всегда, выбор индексов — это поиски оптимального соотношения между скоростью выполнения запроса и стоимостью обновления. В программе Access имеется один тип индекса, а в SQL Server — двенадцать. К счастью, с помощью оптимизатора запросов можно с уверенностью выбрать самый эффективный индекс. В SQL Azure можно воспользоваться автоматическим управлением индексами. Это функция автоматической настройки, которая рекомендует вам добавить или удалить индексы. В отличие от Access, на сервере SQL Server необходимо создать собственные индексы для внешних ключей. Кроме того, чтобы повысить производительность запроса, можно создавать индексы в индексированном представлении. Недостаток индексированного представления заключается в увеличении накладных расходов при изменении данных в базовых таблицах представления, так как представление также необходимо обновлять. Дополнительные сведения см. в публикациях Руководство по архитектуре и дизайну индексов в SQL Server и Индексы.
Транзакции
Выполнять оперативную обработку транзакций (OLTP) трудно с программой Access, но довольно просто с SQL Server. Транзакция — это единица работы с данными, которая фиксирует все изменения данных в случае успеха и откатывает их в случае отказа. У транзакции есть четыре свойства, часто называемые ACID.
-
Атомарность Транзакция — неделимая единица работы. Либо она выполняет все изменения данных, либо ни одного.
-
Согласованность . После выполнения транзакции необходимо оставить все данные в согласованном состоянии. Это означает, что применяются все правила целостности данных.
-
Изоляция Изменения, внесенные параллельными транзакциями, изолированы от текущей транзакции.
-
Устойчивость После завершения транзакции изменения становятся необратимыми даже в случае сбоя системы.
Транзакция используется для обеспечения гарантированной целостности данных, например при снятии наличности в банкомате или автоматическом переводе зарплаты на счет. Транзакции бывают явными, неявными и пакетными. Вот два примера TSQL.
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Дополнительные сведения см. в статье Транзакции.
Ограничения и триггеры
Во всех базах данных есть способы сохранения целостности данных.
Ограничения
В программе Access целостность данных на уровне таблиц обеспечивается с помощью пар ключей (внешний-первичный), каскадного обновления и удаления и правил проверки. Дополнительные сведения смотрите в публикациях Руководство по связям между таблицами и Ограничение ввода данных с помощью правил проверки.
В SQL Server используются ограничения UNIQUE и CHECK. Это объекты базы данных, обеспечивающие целостность данных в таблицах SQL Server. Чтобы проверить, допустимо ли значение в другой таблице, используйте ограничение внешнего ключа. Чтобы проверить, находится ли значение в столбце в пределах определенного диапазона, используйте проверочное ограничение. Такие объекты — первая линия обороны, и они предназначены для эффективной работы. Дополнительные сведения см. в статье Ограничения уникальности и проверочные ограничения.
Триггеры
В программе Access отсутствуют триггеры базы данных. В SQL Server можно использовать триггеры, чтобы выполнять правила целостности сложных данных и эту бизнес-логику. Триггер базы данных — это хранимая процедура, которая выполняется при определенных действиях в базе данных. Триггер — это событие, например добавление или удаление записи в таблице, которое запускает и выполняет хранимую процедуру. Хотя база данных Access может обеспечить целостность данных, когда пользователь обновляет или удаляет данные, сервер SQL Server поддерживает усовершенствованный набор триггеров. Например, можно запрограммировать триггеры, чтобы массово удалить записи и обеспечить целостность данных. Триггеры даже можно добавлять в таблицы и представления.
Дополнительные сведения см. в статьях Триггеры DML, Триггеры DDL и Создание триггера T-SQL.
Вычисляемые столбцы
В программе Access можно создать вычисляемый столбец, если добавить его в запрос и построить выражение, например:
Extended Price: [Quantity] * [Unit Price]
Эквивалентная функция в SQL Server называется вычисляемый столбец. Это виртуальный столбец, который физически не сохраняется в таблице, если он не помечен как PERSISTED. Как и вычисляемый столбец в программе Access, он использует в выражении данные из других столбцов. Чтобы создать вычисляемый столбец, добавьте его в таблицу. Пример.
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Дополнительные сведения см. в статье Выбор вычисляемых столбцов в таблице.
Добавление метки времени
При создании записи иногда можно добавить поле таблицы для метки времени, чтобы вести журнал ввода данных. В программе Access, можно просто создать столбец даты со значением по умолчанию =Now(). Чтобы записать дату или время в SQL Server, используйте тип данных datetime2 со значением по умолчанию SYSDATETIME().
Примечание Важно не путать значения rowversion и timestamp при работе с данными. Ключевое слово timestamp — это синоним rowversion в SQL Server, но использовать следует ключевое слово rowversion. В SQL Server столбец rowversion — это тип данных, который представляет собой автоматически созданные уникальные двоичные числа в базе данных. Он обычно используется для добавления штампа версии строк в таблице. Тип данных rowversion — это только увеличивающееся число, которое не сохраняет дату и время и не предназначено для добавления метки времени строки.
Дополнительные сведения см. в статье Rowversion. Дополнительные сведения о том, как использовать rowversion, чтобы минимизировать конфликты записи, см. в статье Миграция базы данных Access на сервер SQL Server.
Управление большими объектами
В Access вы управляете неструктурированными данными, такими как файлы, фотографии и изображения, используя тип данных вложения. Согласно терминологии SQL Server, неструктурированные данные называются BLOB-объектами (большими двоичными объектами), и с ними можно работать несколькими способами.
FILESTREAM Использует тип данных varbinary (максимальный размер), чтобы сохранять неструктурированные данные в файловой системе, а не в базе данных. Дополнительные сведения см. в статье Доступ к данным FILESTREAM с помощью Transact-SQL.
FileTable Сохраняет большие двоичные объекты в специальных таблицах, которые называются FileTable, и обеспечивает совместимость с приложениями Windows, как если бы они хранились в файловой системе, без изменений в клиентских приложениях. В таблицах FileTable используется FILESTREAM. Дополнительные сведения см. в статье FileTables.
Удаленное хранилище BLOB-объектов (RBS) Сохраняет большие двоичные объекты (BLOB-объекты) в аппаратно-базируемых хранилищах, а не прямо на сервере. Это позволяет сэкономить место и аппаратные ресурсы. Дополнительные сведения см. в статье Данные о больших двоичных объектах (BLOB-объектах).
Работа с иерархическими данными
Хотя реляционные базы данных, такие как Access, очень гибкие, работа с иерархическими отношениями — это исключение, часто требующее сложные инструкции или код SQL. Примеры иерархических данных: организационная структура, файловая система, таксономия языковых терминов и график связей между веб-страницами. Чтобы легко хранить и запрашивать иерархические данные, а также управлять ими, SQL Server имеет встроенный тип данных hierarchyid и набор иерархических функций.
Дополнительные сведения см. в статье Иерархические данные и в Руководстве по использованию типа данных hierarchyid.
Работа с текстом JSON
Нотация объектов JavaScript (JSON) — это веб-служба, которая использует удобочитаемый текст для передачи данных в виде пар “атрибут-значение” с помощью асинхронной связи “браузер-сервер”. Пример.
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
В Access нет встроенных способов управления данными JSON, но в SQL Server вы можете без проблем хранить, индексировать, запрашивать и извлекать данные JSON. Текст JSON можно преобразовать в таблицу и сохранить, а можно форматировать данные непосредственно в тексте JSON. Например, вам может потребоваться отформатировать результаты запроса в формате JSON для веб-приложения или добавить структуры данных JSON в строки и столбцы.
Примечание JSON не поддерживается в VBA. В качестве альтернативы можно использовать формат XML в VBA с помощью библиотеки MSXML.
Дополнительные сведения см. в статье Данные JSON в SQL Server.
Ресурсы
Теперь самое время больше узнать о SQL Server и языке Transact SQL (TSQL). Как видно, в SQL Server есть много таких же функций, как в программе Access, а также возможности, которых в Access нет. Чтобы расширить свои знания, вы можете ознакомиться с приведенными ниже ресурсами.
|
Ресурс |
Описание |
|
Видеокурс |
|
|
Практические занятия по использованию SQL Server 2017 |
|
|
Учебный курс по использованию Azure |
|
|
Станьте экспертом |
|
|
Основная целевая страница |
|
|
Справочная информация |
|
|
Справочная информация |
|
|
Основное руководство по использованию облачных данных (электронная книга) |
Общие сведения об облаке |
|
Визуальное представление новых функций |
|
|
Краткий обзор функций по версиям |
|
|
Скачивание SQL Server Express 2017 |
|
|
Скачать примеры баз данных |









