
Programmā Excel varat izveidot datu modeļus, kas satur miljoniem rindu, un pēc tam veikt jaudīgu datu analīzi attiecībā uz šiem modeļiem. Datu modeļus var izveidot, izmantojot vai Power Pivot pievienojumprogrammu, lai atbalstītu jebkādu skaitu rakurstabulu, diagrammu un Power View vizualizāciju vienā darbgrāmatā.
Lai gan programmā Excel varat viegli izveidot lielus datu modeļus, to ir vairāki iemesli. Vispirms lieli modeļi, kas satur tabulu un kolonnu daudzpunkti, ir pārslogoti, lai veiktu lielāko daļu analīzes, un tie veido apgrūtinošu lauku sarakstu. Pēc tam lieli modeļi izmanto vērtīgo atmiņu, negatīvi ietekmējot citas lietojumprogrammas un atskaites ar vienādiem sistēmas resursiem. Visbeidzot, Microsoft 365, gan SharePoint Online, gan Excel Web App ierobežo Excel faila lielumu līdz 10 MB. Darbgrāmatas datu modeļiem, kas satur miljoniem rindu, 10 MB ierobežojums tiks sasniegts diezgan ātri. Skatiet rakstu Datu modeļa specifikācija un ierobežojumi.
Šajā rakstā uzzināsit, kā izveidot cieši konstruētu modeli, kas ir vieglāk lietojams ar un izmanto mazāk atmiņas. Ja izmantosit laiku, lai apgūtu labāko praksi efektīva modeļa izstrādē, par paraugu, ko veidojat un izmantojat, no tā neatkarīgi no tā, vai skatāt to programmā Excel, Microsoft 365 SharePoint Online, Office Web Apps Server vai SharePoint.
Apsveriet iespēju izmantot arī darbgrāmatas lieluma optimizētāju. Tas analizē jūsu Excel darbgrāmatu un, ja iespējams, vēl vairāk to saspiež. Lejupielādējiet darbgrāmatas lieluma optimizētāju.
Šajā rakstā
Saspiešanas proporcijas un atmiņas analīzes programma
Datu modeļi programmā Excel izmanto atmiņas analīzes programmu, lai glabātu datus atmiņā. Programma ievieš jaudīgas saspiešanas metodes, lai samazinātu krātuves prasības, samazinot rezultātu kopu, līdz tā ir daļa no tās sākotnējā izmēra.
Vidējā gadījumā datu modelim var būt 7–10 reizes mazāki par tiem pašiem datiem to izcelsmes vietā. Piemēram, ja importējat 7 MB datu no SQL Server datu bāzes, datu modelis programmā Excel var būt vienkārši 1 MB vai mazāks. Faktiski sasniegtā saspiešanas pakāpe ir atkarīga no unikālo vērtību skaita katrā kolonnā. Jo vairāk unikālu vērtību, jo vairāk atmiņas nepieciešams, lai tās saglabātu.
Kāpēc mēs sarunājamies par saspiešanu un unikālām vērtībām? Tā kā efektīvu modeli, kas minimizē atmiņas lietojumu, nozīmē saspiešanas maksimizēšana, un vienkāršākais veids, kā to izdarīt, ir atbrīvoties no kolonnām, kas nav patiešām nepieciešamas, it īpaši, ja šajās kolonnās iekļauts liels skaits unikālu vērtību.
Piezīme.: Atsevišķu kolonnu krātuves prasību atšķirības var būt milzīgas. Dažos gadījumos ir labāk, ja ir vairākas kolonnas ar nelielu unikālo vērtību skaitu, nevis vienu kolonnu ar lielu unikālo vērtību skaitu. Datetime optimizācijas sadaļā detalizēti aplūkota šī metode.
Ja atmiņas lietojums ir zems, nekas nepārspēj kolonnu, kas nepastāv
Visdefektīvākā kolonna ir kolonna, ko nekad neesat importējis pirmajā vietā. Ja vēlaties izveidot efektīvu modeli, aplūkojiet katru kolonnu un pajautājiet sev, vai tā veicina analīzi, kuru vēlaties veikt. Ja tā nav vai jūs neesat pārliecināts, izejiet no tās. Ja nepieciešams, vēlāk var pievienot jaunas kolonnas.
Divi kolonnu piemēri, kas vienmēr ir jāizslēdz
Pirmais piemērs attiecas uz datiem, kas iegūti no datu noliktavas. Datu noliktavā bieži ir atrast ETL procesu artefaktus, kas ielādē un atsvaidzina datus noliktavā. Ielādējot datus, tiek izveidotas kolonnas, piemēram, "izveides datums", "atjaunināšanas datums" un "ETL palaišana". Modelī neviena no šīm kolonnām nav nepieciešama, un datu importēšanas laikā tā ir jāatlasa.
Otrajā piemērā tiek izlaista primārās atslēgas kolonna, importējot faktu tabulu.
Daudzās tabulās, tostarp faktu tabulās, ir primārās atslēgas. Lielākajai daļai tabulu, piemēram, tabulām, kurās ir klientu, darbinieku vai pārdošanas dati, ir nepieciešama tabulas primārā atslēga, lai to varētu izmantot relāciju veidojiet modelī.
Faktu tabulas ir atšķirīgas. Faktu tabulā primārā atslēga tiek izmantota, lai unikāli identificētu katru rindu. Kaut arī normalizēšanas nolūkiem tā ir mazāk noderīga datu modelī, ja vēlaties izmantot tikai tās kolonnas, ko izmanto analīzei vai tabulu relāciju metodēm. Šī iemesla dēļ, importējot no faktu tabulas, neie iekļaut primāro atslēgu. Primārās atslēgas faktu tabulā patērē ļoti daudz vietas modelī, taču tām netiek sniegta priekšrocība, jo tās nevar izmantot relāciju veidojiet.
Piezīme.: Datu noliktavās un daudzdimensiju datu bāzēs lielās tabulas, kurās lielākoties ir skaitliski dati, bieži tiek sauktas par faktu tabulām. Faktu tabulās parasti ietilpst uzņēmuma veiktspējas vai transakciju dati, piemēram, pārdošanas un izmaksu datu punkti, kas ir apkopoti un saskaņoti ar organizācijas vienībām, produktiem, tirgus segmentiem, ģeogrāfiskajiem reģioniem utt. Lai atbalstītu datu analīzi, modelī ir jāiekļauj visas faktu tabulas kolonnas, kurās ir biznesa dati vai ko var izmantot, lai izveidotu iekšējās atsauces uz citās tabulās glabātiem datiem. Kolonna, kuru vēlaties izslēgt, ir faktu tabulas primārās atslēgas kolonna, kas sastāv no unikālām vērtībām, kas pastāv tikai faktu tabulā un nekur citur. Tā kā faktu tabulas ir tik lielas, ka modeļa efektivitāte tiek iegūta, neiekļaujot faktu tabulās esošās rindas vai kolonnas.
Kā izslēgt nevajadzīgas kolonnas
Efektīva modeļos ir tikai tās kolonnas, kas darbgrāmatā faktiski būs vajadzīgas. Ja vēlaties kontrolēt, kuras kolonnas ir iekļautas modelī, izmantojiet pievienojumprogrammas Power Pivot tabulu importēšanas vedni, lai importētu datus, nevis excel dialoglodziņu "Datu importēšana".
Kad startējat tabulu importēšanas vedni, atlasiet importēsamās tabulas.
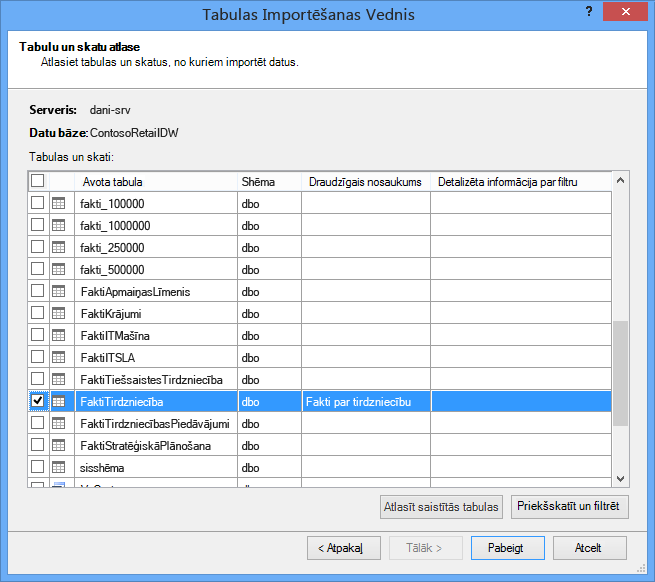
Katrā tabulā varat noklikšķināt uz pogas & filtrēt un atlasīt tās tabulas daļas, kas jums ir vajadzīgas. Ieteicams vispirms noņemt atzīmi visām kolonnām un pēc tam pēc tam pārbaudīt nepieciešamās kolonnas, kad ir iespējams noteikt, vai tās ir nepieciešamas analīzei.
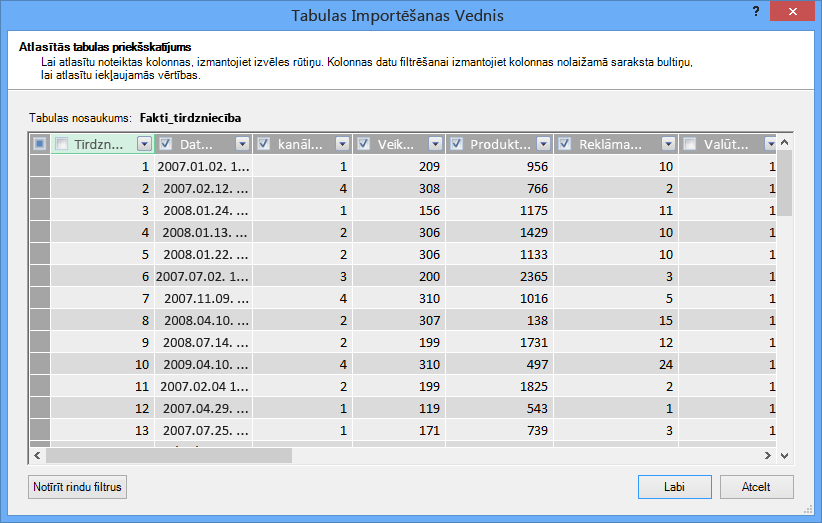
Kā ar tikai nepieciešamo rindu filtrēšanu?
Daudzās korporatīvajās datu bāzēs un datu noliktavās esošās tabulas satur vēsturiskos datus, kas tiek uzkrāti ilgu laika periodu laikā. Turklāt jūs varētu atrast, ka jūs interesētajās tabulās ir iekļauta informācija par uzņēmējdarbības jomām, kas nav nepieciešamas jūsu konkrētai analīzei.
Izmantojot tabulu importēšanas vedni, varat atfiltrēt vēsturiskos vai nesaistītos datus un tādējādi ietaupīt daudz vietas modelī. Nākamajā attēlā datuma filtrs tiek izmantots, lai izgūtu tikai rindas, kurās ir pašreizējā gada dati, bet ne vēsturiskos datus, kas nebūs nepieciešami.
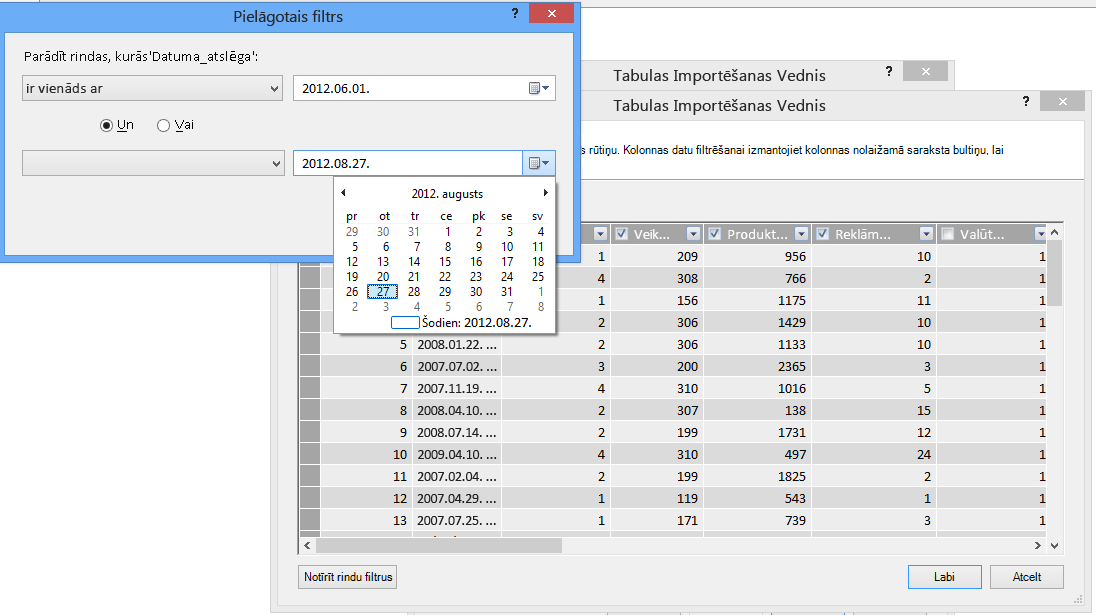
Kā darīt, ja kolonna ir nepieciešama; vai mēs joprojām varam samazināt savas vietas izmaksas?
Ir vēl dažas metodes, ko varat izmantot, lai kolonnu padarītu par labāku saspiešanu. Atcerieties, ka vienīgā kolonnas pazīme, kas ietekmē saspiešanu, ir unikālo vērtību skaits. Šajā sadaļā uzzināsit, kā var modificēt dažas kolonnas, lai samazinātu unikālo vērtību skaitu.
Datetime kolonnu modificēšana
Daudzos gadījumos datetime kolonnās ir daudz brīvas vietas. Par laimi, pastāv vairāki veidi, kā samazināt datu tipa krātuves prasības. Metodes būs atkarīgas no kolonnas izmantošanas un jūsu ērtības līmeņa SQL vaicājumu veidošanā.
Datuma/laika kolonnās ir iekļauta datuma daļa un laiks. Ja jautājiet sev, vai jums ir nepieciešama kolonna, uzdodiet vienu un to pašu jautājumu vairākas reizes datuma laika kolonnai:
-
Vai ir nepieciešama laika daļa?
-
Vai ir nepieciešama laika daļa stundu līmenī? Minūtes? Sekundes? Milisekundes?
-
Vai man ir vairākas datuma/laika kolonnas, jo vēlos aprēķināt starpību starp tām vai vienkārši, lai apkopotu datus pēc gada, mēneša, ceturkšņa utt.
Atbildēšana uz katru no šiem jautājumiem nosaka jūsu iespējas darbs ar kolonnu Datetime.
Visos šajos risinājumos ir nepieciešama SQL vaicājuma modificēšana. Lai atvieglotu vaicājumu modificēšanu, katrā tabulā ir jāfiltrē vismaz viena kolonna. Filtrējot kolonnu, tiek mainīta vaicājuma izveide no saīsināta formāta (SELECT *) uz priekšrakstu SELECT, kurā iekļauti pilnībā kvalificēti kolonnu nosaukumi, ko ir daudz vieglāk modificēt.
Apskatīsim jums izveidotos vaicājumus. Dialoglodziņā Tabulas rekvizīti varat pārslēgties uz vaicājumu redaktoru un skatīt katras tabulas pašreizējo SQL vaicājumu.
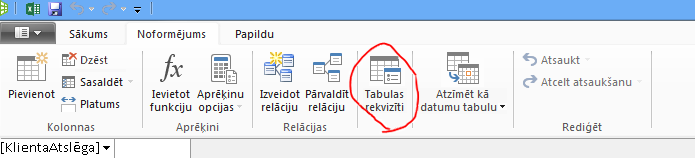
Sadaļā Tabulas rekvizīti atlasiet Vaicājumu redaktors.
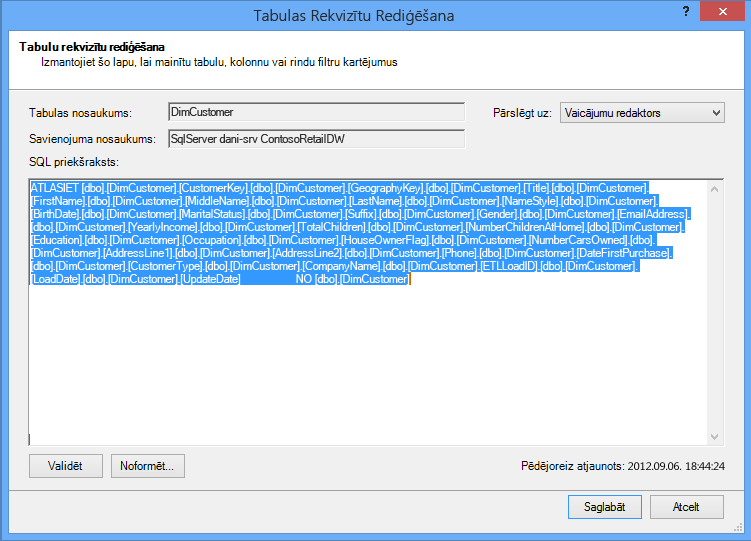
Vaicājumu redaktors parāda SQL vaicājumu, kas tiek izmantots tabulas aizpildīšanai. Ja importēšanas laikā filtrējat jebkuru kolonnu, vaicājumā tiek iekļauti pilnībā kvalificēti kolonnu nosaukumi.
|
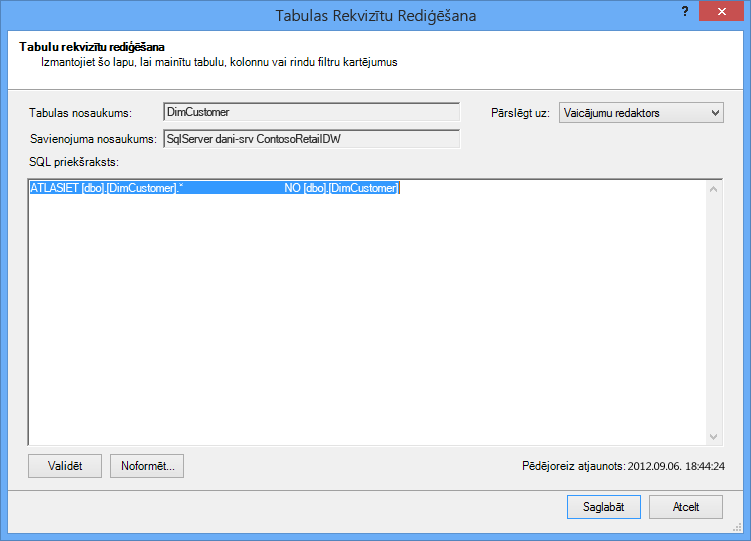
Savukārt, ja importējāt tabulu pilnībā, nenoņemot atzīmi nevienai kolonnai un lietojot filtru, vaicājums tiks rādīts kā "Atlasīt * no", kas būs grūtāk modificējams:
|
SQL vaicājuma modificēšana
Tagad, kad zināt, kā atrast vaicājumu, varat to modificēt, lai vēl vairāk samazinātu modeļa lielumu.
-
Kolonnām, kurās ir valūtas vai decimālskaitļu dati, ja decimālskaitļi nav nepieciešami, lietojiet šo sintaksi, lai atbrīvotos no decimāldaļām:
"SELECT ROUND([Decimal_column_name],0)... .”
Ja ir nepieciešami centi, bet ne centi, aizstājiet 0 ar 2. Ja izmantojat negatīvus skaitļus, varat noapaļot līdz vienībām, desmitiem, simtiem utt.
-
Ja jums ir kolonna Datetime ar nosaukumu dbo. Bigtable. [Datuma laiks] un nav nepieciešama daļa Laiks, izmantojiet sintaksi, lai atbrīvotos no laika:
"SELECT CAST (dbo. Bigtable. [Date time] as date) AS [Date time]) "
-
Ja jums ir kolonna Datetime ar nosaukumu dbo. Bigtable. [Datuma laiks] un ir nepieciešamas gan datuma, gan laika daļas, SQL vaicājumā izmantojiet vairākas kolonnas, nevis vienu kolonnu Datumslaiks:
"SELECT CAST (dbo. Bigtable. [Date Time] as date ) AS [Date Time],
datepart(hh, dbo. Bigtable. [Datuma laiks]) kā [Datuma laika stundas],
datepart(mi, dbo. Bigtable. [Datuma laiks]) kā [Datuma laika minūtes],
datepart(ss, dbo. Bigtable. [Datuma laiks]) kā [Datuma laika sekundes],
datepart(ms, dbo. Bigtable. [Datuma laiks]) kā [Datuma laiks milisekundēs]"
Izmantojiet tik daudz kolonnu, cik nepieciešams, lai glabātu katru daļu atsevišķās kolonnās.
-
Ja nepieciešamas stundas un minūtes un vēlaties tās izmantot kopā kā vienu laika kolonnu, varat izmantot sintaksi:
Timefromparts(datepart(hh, dbo. Bigtable. [Date Time]), datepart(mm, dbo. Bigtable. [Datums laiks])) kā [Date Time HourMinute]
-
Ja jums ir divas datuma/laika kolonnas, piemēram, [Sākuma laiks] un [Beigu laiks], un jums ir vajadzīga laika starpība starp tām sekundēs kā kolonnu ar nosaukumu [Ilgums], noņemiet abas kolonnas no saraksta un pievienojiet:
"datediff(ss,[Start Date],[End Date]) as [Duration]"
Ja izmantojat atslēgvārdu ms, nevis s, jūs iegūstat ilgumu milisekundēs
DAX aprēķināto izmēru izmantošana kolonnu vietā
Ja iepriekš strādājāt ar DAX izteiksmes valodu, iespējams, jau zināt, ka aprēķinātās kolonnas tiek izmantotas, lai noteiktu jaunas kolonnas kādā citā modeļa kolonnā, savukārt aprēķinātie mēra iestatījumi modelī tiek definēti vienreiz, bet tiek novērtēti tikai tad, ja tiek izmantoti rakurstabulā vai citā atskaitē.
Viena atmiņas saglabāšanas metode ir parasto vai aprēķināto kolonnu aizstāšana ar aprēķinātajiem mēram. Klasiskais piemērs ir Vienības cena, Daudzums un Kopsumma. Ja jums ir visas trīs vietas, varat ietaupīt vietu, uzturot tikai divus un aprēķinot trešo, izmantojot DAX.
Kuras 2 kolonnas ir jāsaglabā?
Iepriekš minētajā piemērā paturiet saglabāt daudzumu un vienības cenu. Šiem diviem ir mazāk vērtību nekā kopsummai. Lai aprēķinātu kopsummu, pievienojiet aprēķināto mērvienību, piemēram:
"TotalSales:=sumx('Sales Table','Sales Table'[Unit Price]*'Sales Table'[Quantity])"
Aprēķinātās kolonnas ir kā parastas kolonnas, kas abas aizņem vietu modelī. Savukārt aprēķinātie mēra aprēķini tiek aprēķināti lidojuma laikā un aizņem vietu.
Secinājums
Šajā rakstā mēs runājām par vairākām pieejām, kas var palīdzēt jums veidot efektīvāku atmiņas modeli. Veids, kā samazināt datu modeļa faila lielumu un atmiņas prasības, ir samazināt kopējo kolonnu un rindu skaitu, kā arī katrā kolonnā parādīto unikālo vērtību skaitu. Tālāk ir aplūkotas dažas metodes.
-
Kolonnu noņemšana, protams, ir vislabākais veids, kā ietaupīt vietu. Izlemiet, kuras kolonnas ir nepieciešamas.
-
Dažreiz varat noņemt kolonnu un aizstāt to ar aprēķināto mēru tabulā.
-
Iespējams, ka jums nebūs vajadzīgas visas tabulas rindas. Tabulas importēšanas vednī varat filtrēt rindas.
-
Parasti atsevišķas kolonnas sadalīšana vairākās dažādās daļās ir labs veids, kā samazināt unikālo vērtību skaitu kolonnā. Katrai no daļām būs neliels unikālo vērtību skaits, un kopējā kopsumma būs mazāka par sākotnējo vienoto kolonnu.
-
Daudzos gadījumos ir nepieciešamas arī atsevišķas daļas, ko izmantot kā datu griezumus jūsu atskaitēs. Ja nepieciešams, varat izveidot hierarhijas no daļām, piemēram, Stundas, Minūtes un Sekundes.
-
Daudzos gadījumos kolonnās ir vairāk informācijas, nekā nepieciešams. Piemēram, pieņemsim, ka kolonnā tiek glabāti decimālskaitļi, bet esat pielietojis formatējumu, lai paslēptu visus decimāldaļskaitļus. Noapaļošana var būt ļoti efektīva, samazinot skaitliskās kolonnas lielumu.
Tagad, kad esat pabeidzis, ko varat darīt, lai samazinātu darbgrāmatas lielumu, apsveriet iespēju izmantot arī darbgrāmatas lieluma optimizētāju. Tas analizē jūsu Excel darbgrāmatu un, ja iespējams, vēl vairāk to saspiež. Lejupielādējiet darbgrāmatas lieluma optimizētāju.
Saistītās saites
Datu modeļa specifikācija un ierobežojumi
Darbgrāmatas lieluma optimizētājs
PowerPivot: jaudīga datu analīze un datu modelēšana programmā Excel









