
이 문서에서는 Microsoft Excel의 SKEW.P 함수에 사용되는 수식 구문과 이 함수를 사용하는 방법을 설명합니다.
설명
모집단을 기준으로 분포의 왜곡도를 반환합니다. 왜곡도란 평균에 대한 분포의 비대칭 정도를 나타냅니다.
구문
SKEW.P(number 1, [number 2],…)
SKEW.P 함수 구문에는 다음과 같은 인수가 사용됩니다.
번호 1, 숫자 2,... 숫자 1이 필요하며 후속 숫자는 선택 사항입니다. 번호 1, 숫자 2,... 은 1~254개의 숫자 또는 이름, 배열 또는 모집단 기울이기를 원하는 숫자를 포함하는 참조입니다.
SKEW.P는 다음과 같이 계산됩니다.
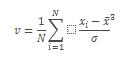
주의
-
인수는 숫자이거나 숫자를 포함한 이름, 배열 또는 참조 영역일 수 있습니다.
-
인수 목록에 직접 입력하는 논리값, 텍스트로 나타낸 숫자 등은 계산에 포함됩니다.
-
배열 또는 참조 인수에 텍스트, 논리값 또는 빈 셀이 있는 경우 이러한 값은 포함되지 않지만 값이 0인 셀은 포함됩니다.
-
SKEW.P는 표본 집단이 아니라 전체 모집단의 표준 편차를 사용합니다.
-
인수가 유효하지 않은 값이면 SKEW.P에서는 #NUM! 오류 값이 반환됩니다.
-
인수가 유효하지 않은 데이터 형식을 사용하면 SKEW.P에서는 #VALUE! 오류 값이 반환됩니다.
-
데이터 수가 3개 미만이거나 표본 표준 편차가 0이면 SKEW.P에서는 #DIV/0! 오류 값이 반환됩니다.
예제
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. 수식의 결과를 표시하려면 수식을 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
|
모집단 데이터 집합 |
||
|
3 |
||
|
4 |
||
|
5 |
||
|
2 |
||
|
3 |
||
|
4 |
||
|
5 |
||
|
6 |
||
|
4 |
||
|
7 |
||
|
수식 |
설명 |
결과 |
|
=SKEW.P(A2:A11) |
A2:A11의 데이터 집합 모집단을 기준으로 하는 분포의 왜곡도입니다(0.303193). |
0.303193 |









