
지정된 평균과 표준 편차를 갖는 정규 분포값을 반환합니다. 이 함수는 가설 검정 등 통계의 광범위한 영역에서 응용됩니다.
구문
NORM.DIST(x,mean,standard_dev,cumulative)
NORM.DIST 함수 구문에는 다음과 같은 인수가 사용됩니다.
-
X 필수 요소입니다. 분포를 구하려는 값입니다.
-
mean 필수 요소입니다. 분포의 산술 평균입니다.
-
standard_dev 필수 요소입니다. 분포의 표준 편차입니다.
-
cumulative 필수 요소입니다. 함수의 형식을 결정하는 논리 값입니다. 누적이 TRUE이면 NORM입니다. DIST는 누적 분포 함수를 반환합니다. FALSE이면 확률 밀도 함수를 반환합니다.
주의
-
mean 또는 standard_dev가 숫자가 아니면 NORM.DIST에서 #VALUE! 오류 값이 반환됩니다.
-
standard_dev ≤ 0이면 NORM.DIST에서 #NUM! 오류 값이 반환됩니다.
-
mean = 0, standard_dev = 1이고 cumulative = TRUE이면 NORM.DIST에서 표준 정규 분포인 NORM.S.DIST 함수가 반환됩니다.
-
정규 밀도 함수(cumulative = FALSE)는 다음과 같이 계산됩니다.
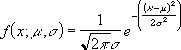
-
cumulative = TRUE일 때 이 수식은 주어진 수식을 음수 무한대에서 x까지 적분한 값입니다.
예제
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. 수식의 결과를 표시하려면 수식을 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
|
데이터 |
설명 |
|
|
42 |
확률 분포를 계산할 기준 값입니다. |
|
|
40 |
분포의 산술 평균입니다. |
|
|
1.5 |
분포의 표준 편차입니다. |
|
|
수식 |
설명 |
결과 |
|
=NORM.DIST(A2,A3,A4,TRUE) |
위 조건에 대한 누적 분포 함수를 반환합니다. |
0.9087888 |
|
=NORM.DIST(A2,A3,A4,FALSE) |
위 조건에 대한 확률 질량 함수를 반환합니다. |
0.10934 |









