
이 문서에서는 Microsoft Excel의 COVARIANCE.P 함수에 사용되는 수식 구문과 이 함수를 사용하는 방법을 설명합니다.
두 데이터 집합의 각 데이터 요소 쌍에 대한 편차의 곱의 평균(모집단 공분산)을 반환합니다. 공분산을 사용하면 두 데이터 집합 사이의 관계를 확인할 수 있습니다. 예를 들어 수입이 높을수록 교육 수준이 높은지 여부를 확인할 수 있습니다.
구문
COVARIANCE.P(array1,array2)
COVARIANCE.P 함수 구문에는 다음과 같은 인수가 사용됩니다.
-
array1 필수 요소입니다. 첫 번째 정수 셀 범위입니다.
-
array2 필수 요소입니다. 두 번째 정수 셀 범위입니다.
주의
-
인수는 숫자이거나 숫자가 들어 있는 이름, 배열 또는 참조여야 합니다.
-
배열 또는 참조 인수에 텍스트, 논리값 또는 빈 셀이 있는 경우 이러한 값은 포함되지 않지만 값이 0인 셀은 포함됩니다.
-
array1과 array2의 데이터 요소의 수가 다르면 COVARIANCE.P에서는 #N/A 오류 값이 반환됩니다.
-
array1과 array2가 비어 있으면 COVARIANCE.P에서는 #DIV/0! 오류 값이 반환됩니다.
-
공분산은 다음과 같이 계산됩니다.
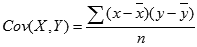
여기서
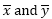
는 표본 평균 AVERAGE(array1)과 AVERAGE(array2)이고 n은 표본 크기입니다.
예제
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. 수식의 결과를 표시하려면 수식을 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
|
데이터1 |
데이터2 |
|
|
3 |
9 |
|
|
2 |
7 |
|
|
4 |
12 |
|
|
5 |
15 |
|
|
6 |
17 |
|
|
수식 |
설명 |
결과 |
|
=COVARIANCE.P(A2:A6, B2:B6) |
공분산, 즉 위의 각 데이터 요소 쌍에 대한 편차의 곱의 평균입니다. |
5.2 |









