
LEFT、MID、RIGHT、SEARCH、LEN の各テキスト関数を使用して、データ内のテキストの文字列を操作できます。 たとえば、1 つのセルの先頭、中央、および姓を 3 つの個別の列に分散できます。
テキスト関数を使用して名前コンポーネントを分散するキーは、テキスト文字列内の各文字の位置です。 文字列内のスペースの位置も重要です。これは、文字列内の名前コンポーネントの先頭または末尾を示すからです。
たとえば、姓と名のみを含むセルでは、姓はスペースの最初のインスタンスの後から始まります。 リスト内の一部の名前にはミドル ネームが含まれている場合があります。その場合、姓はスペースの 2 番目のインスタンスの後から始まります。
この記事では、これらの便利な関数を使用して、さまざまな名前形式からさまざまなコンポーネントを抽出する方法について説明します。 テキストを列に変換ウィザードを使用して、テキストを異なる列に分割することもできます
|
名前の例 |
説明 |
名 |
ミドル ネーム |
姓 |
サフィックス |
|
|
1 |
ミドル ネームなし |
由香 |
木山 勇 |
|||
|
2 |
1 つの中間の初期 |
Eric |
S. |
Kurjan |
||
|
3 |
2 つの中間イニシャル |
Janaina |
B. G. |
ブエノ |
||
|
4 |
名の先頭にコンマを付けます |
ウェンディ |
ベス |
カーン |
||
|
5 |
2 部構成の名 |
メアリーケイ |
D. |
Andersen |
||
|
6 |
3 部構成の姓 |
ポーラ |
バレート デ マトス |
|||
|
7 |
2 部構成の姓 |
ジェームズ |
van Eaton |
|||
|
8 |
姓とサフィックスの先頭にコンマを付けます |
ダン |
K. |
ベーコン |
ジェイアール。 |
|
|
9 |
サフィックス付き |
ゲーリー |
アルトマン |
III |
||
|
10 |
プレフィックス付き |
Ryan |
Ihrig |
|||
|
11 |
ハイフンで区切られた姓 |
原田 |
Taft-Rider |
注: 次の例の図では、完全な名前の強調表示は、一致する SEARCH 式が探している文字を示しています。
この例では、名と姓の 2 つのコンポーネントを区切ります。 2 つの名前は 1 つのスペースで区切られます。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
Jeff Smith |
ミドル ネームなし |
|
数式 |
結果 (名) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (姓) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
-
名
名は、文字列内の先頭の文字 (J) から始まり、5 文字目 (スペース) で終わります。 次の式は、セル A2 の左から 5 文字を返します。
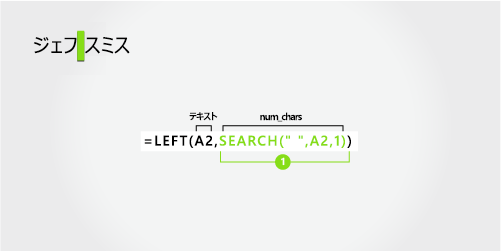
SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
A2 に含まれるスペースの位置を左から検索します。
-
姓
姓は、右から 5 文字目のスペースから始まり、右端の文字 (h) で終了します。 次の式は、A2 の右から 5 文字を抽出します。

SEARCH 関数と LEN 関数を使って、"文字数" 引数に渡す値を取得します。
A2 に含まれるスペースの位置を左から検索します。 (5)
-
文字列全体の長さを取得し、その文字数と、手順 1 で検索した最初のスペースの左までの文字数との差を求めます。
この例では、名、中間の頭文字、姓を使用します。 各名前コンポーネントはスペースで区切られます。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
Eric S. Kurjan |
1 つの中間の初期 |
|
数式 |
結果 (名) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (中間初期) |
|
'=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)-SEARCH(" ",A2,1)) |
=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,1)+1)-SEARCH(" ",A2,1)) |
|
数式 |
ライブ結果 (姓) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
-
名
最初の名前は、左 (E) の最初の文字で始まり、5 番目の文字 (最初のスペース) で終わります。 数式は、A2 の最初の 5 文字を左から抽出します。

SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
A2 に含まれるスペースの位置を左から検索します。 (5)
-
ミドル ネーム
ミドル ネームは 6 番目の文字位置 (S) から始まり、8 番目の位置 (2 番目のスペース) で終わります。 この数式では、SEARCH 関数を入れ子にして、スペースの 2 番目のインスタンスを検索します。
数式は、6 番目の位置から 3 文字を抽出します。
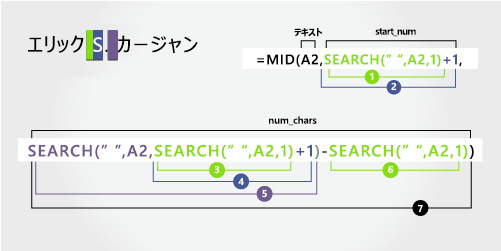
SEARCH 関数を使って、"開始位置" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (5).
-
1 を追加して、最初のスペース (S) の後の文字の位置を取得します。 この数値の位置は、ミドル ネームの開始位置です。 (5 + 1 = 6)
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (5)
-
1 を追加して、最初のスペース (S) の後の文字の位置を取得します。 結果は、スペースの 2 番目のインスタンスの検索を開始する文字数です。 (5 + 1 = 6)
-
手順 4 で見つかった 6 番目の位置 (S) から始まる、A2 内のスペースの 2 番目のインスタンスを検索します。 この文字番号は、ミドル ネームの終了位置です。 (8)
-
左側の最初の文字から始まる、A2 のスペースの数値位置を検索します。 (5)
-
手順 5 で見つかった 2 番目のスペースの文字数を取り、手順 6 で見つかった最初のスペースの文字数を減算します。 結果は、手順 2 で見つかった 6 番目の位置から始まるテキスト文字列から MID が抽出した文字数です。 (8 – 5 = 3)
-
姓
姓は右から 6 文字 (K) で始まり、右側 (n) の最初の文字で終わります。 この数式では、SEARCH 関数を入れ子にして、スペースの 2 番目と 3 番目のインスタンス (左側から 5 番目と 8 番目の位置) を検索します。
数式では、A2 で右側から 6 文字が抽出されます。
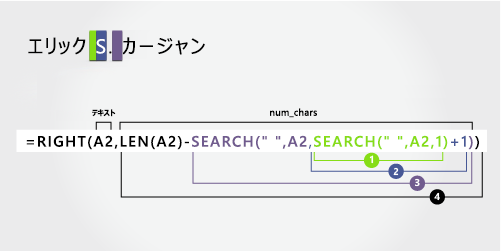
-
LEN 関数と入れ子になった SEARCH 関数を使用して、num_charsの値を検索します。
左側の最初の文字から始まる、A2 のスペースの数値位置を検索します。 (5)
-
1 を追加して、最初のスペース (S) の後の文字の位置を取得します。 結果は、スペースの 2 番目のインスタンスの検索を開始する文字数です。 (5 + 1 = 6)
-
手順 2 で見つかった 6 番目の位置 (S) から始まる、A2 内のスペースの 2 番目のインスタンスを検索します。 この文字番号は、ミドル ネームの終了位置です。 (8)
-
A2 のテキスト文字列の長さの合計をカウントし、手順 3 で見つかった領域の 2 番目のインスタンスまでの左から文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (14 – 8 = 6)。
2 つの中間イニシャルを抽出する方法の例を次に示します。 スペースの最初と 3 番目のインスタンスは、名前コンポーネントを区切ります。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
Janaina B. G. ブエノ |
2 つの中間イニシャル |
|
数式 |
結果 (名) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (中間イニシャル) |
|
'=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)-SEARCH(" ",A2,1)) |
=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)-SEARCH(" ",A2,1)) |
|
数式 |
ライブ結果 (姓) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)) |
-
名
最初の名前は、左 (J) の最初の文字で始まり、8 番目の文字 (最初のスペース) で終わります。 数式は、A2 の最初の 8 文字を左から抽出します。

SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (8)
-
ミドル ネーム
ミドル ネームは 9 番目の位置 (B) から始まり、14 番目の位置 (3 番目のスペース) で終わります。 この数式では、SEARCH を入れ子にして、8 番目、11 番目、14 番目の位置のスペースの最初、2 番目、および 3 番目のインスタンスを検索します。
数式は、9 番目の位置から 5 文字を抽出します。
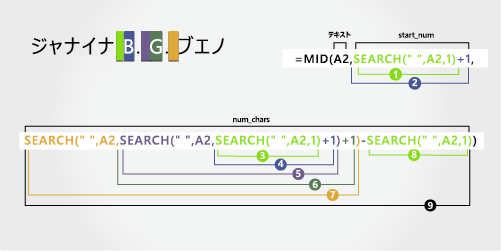
SEARCH 関数を使って、"開始位置" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (8)
-
1 を追加して、最初のスペース (B) の後の文字の位置を取得します。 この数値の位置は、ミドル ネームの開始位置です。 (8 + 1 = 9)
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (8)
-
1 を追加して、最初のスペース (B) の後の文字の位置を取得します。 結果は、スペースの 2 番目のインスタンスの検索を開始する文字数です。 (8 + 1 = 9)
-
手順 4 で見つかった 9 番目の位置 (B) から始まる、A2 の 2 番目のスペースを検索します。 (11).
-
1 を追加して、2 番目のスペース (G) の後の文字の位置を取得します。 この文字番号は、3 番目のスペースの検索を開始する開始位置です。 (11 + 1 = 12)
-
手順 6 で見つかった 12 番目の位置から、A2 の 3 番目のスペースを検索します。 (14)
-
A2 の最初のスペースの数値位置を検索します。 (8)
-
手順 7 で見つかった 3 番目のスペースの文字数を取り、手順 6 で見つかった最初のスペースの文字数を減算します。 結果は、手順 2 で見つかった 9 番目の位置から始まるテキスト文字列から MID が抽出した文字数です。
-
姓
姓は右から 5 文字 (B) で始まり、右側の最初の文字 (o) で終わります。 この数式では、SEARCH を入れ子にして、スペースの最初、2 番目、および 3 番目のインスタンスを検索します。
数式では、完全な名前の右側から始まる、A2 で 5 文字が抽出されます。
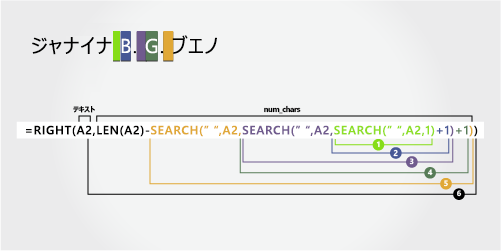
入れ子になった SEARCH 関数と LEN 関数を使用して、num_charsの値を検索します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (8)
-
1 を追加して、最初のスペース (B) の後の文字の位置を取得します。 結果は、スペースの 2 番目のインスタンスの検索を開始する文字数です。 (8 + 1 = 9)
-
手順 2 で見つかった 9 番目の位置 (B) から始まる、A2 の 2 番目のスペースを検索します。 (11)
-
1 を追加して、2 番目のスペース (G) の後の文字の位置を取得します。 この文字番号は、スペースの 3 番目のインスタンスの検索を開始する開始位置です。 (11 + 1 = 12)
-
手順 6 で見つかった 12 番目の位置 (G) から、A2 で 3 番目のスペースを検索します。 (14)
-
A2 のテキスト文字列の長さの合計をカウントし、手順 5 で見つかった 3 番目のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (19 - 14 = 5)
この例では、名の前に姓があり、最後にミドル ネームがあります。 コンマは姓の末尾にマークを付け、スペースは各名前コンポーネントを区切ります。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
カーン、ウェンディ・ベス |
名の先頭にコンマを付けます |
|
数式 |
結果 (名) |
|
'=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)-SEARCH(" ",A2,1)) |
=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,1)+1)-SEARCH(" ",A2,1)) |
|
数式 |
結果 (ミドル ネーム) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
|
数式 |
ライブ結果 (姓) |
|
'=LEFT(A2, SEARCH(" ",A2,1)-2) |
=LEFT(A2, SEARCH(" ",A2,1)-2) |
-
名
名は、左から 7 文字目 (W) から始まり、12 文字目 (2 つ目のスペース) で終わります。 名は氏名の中央にあるため、MID 関数を使って抽出する必要があります。
数式では、7 番目の位置から 6 文字が抽出されます。
SEARCH 関数を使って、"開始位置" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (6)
-
1 を追加して、最初のスペース (W) の後の文字の位置を取得します。 この数値の位置は、名の開始位置です。 (6 + 1 = 7)
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (6)
-
1 を追加して、最初のスペース (W) の後の文字の位置を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (6 + 1 = 7)
手順 4 で見つかった 7 番目の位置 (W) から開始して、A2 の 2 番目のスペースを検索します。 (12)
-
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (6)
-
手順 5 で見つかった 2 番目のスペースの文字数を取り、手順 6 で見つかった最初のスペースの文字数を減算します。 結果は、手順 2 で見つかった 7 番目の位置から始まるテキスト文字列から MID が抽出した文字数です。 (12 - 6 = 6)
-
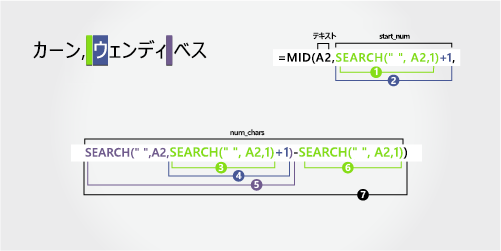
ミドル ネーム
ミドル ネームは、右から 4 文字目 (B) から始まり、右端の文字 (h) で終わります。 次の式では、ネストされた SEARCH 関数を使って、左から 6 文字目にある最初のスペースと左から 12 文字目にある 2 つ目のスペースを取得します。
数式では、右側から 4 文字が抽出されます。
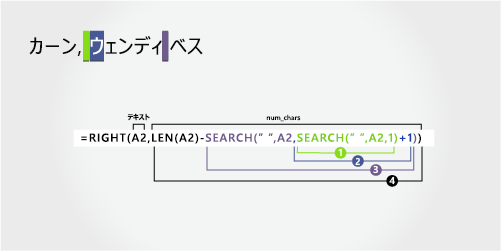
ネストされた SEARCH 関数と LEN 関数を使って、"開始位置" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (6)
-
1 を追加して、最初のスペース (W) の後の文字の位置を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (6 + 1 = 7)
-
手順 2 で見つかった 7 番目の位置 (W) から始まる A2 のスペースの 2 番目のインスタンスを検索します。 (12)
-
A2 のテキスト文字列の長さの合計をカウントし、手順 3 で見つかった左から 2 番目のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (16 - 12 = 4)
-
姓
姓は、左端の文字 (K) から始まり、4 文字目 (n) で終わります。 次の式は、左から 4 文字を抽出します。

SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (6)
-
2 を減算して、姓 (n) の終了文字の数値位置を取得します。 結果は、LEFT で抽出する文字数です。 (6 - 2 =4)
この例では、2 部構成の名である Mary Kay を使用します。 2 番目と 3 番目のスペースは、各名前コンポーネントを区切ります。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
メアリー ケイ D. アンダーセン |
2 部構成の名 |
|
数式 |
結果 (名) |
|
LEFT(A2, SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
=LEFT(A2, SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
|
数式 |
結果 (中間初期) |
|
'=MID(A2,SEARCH(" ",A2,1)+1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)-(SEARCH(" ",A2,1)+1)+1)-(SEARCH(" ",A2,1)+1)+1)) |
=MID(A2,SEARCH(" ",A2,1)+1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)-(SEARCH(" ",A2,1)+1)+1)-(SEARCH(" ",A2,1)+1)+1)) |
|
数式 |
ライブ結果 (姓) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)) |
-
名
最初の名前は、左側の最初の文字で始まり、9 番目の文字 (2 番目のスペース) で終わります。 この数式では、SEARCH を入れ子にして、左側から 2 番目のスペース インスタンスを見つけます。
数式では、左から 9 文字が抽出されます。
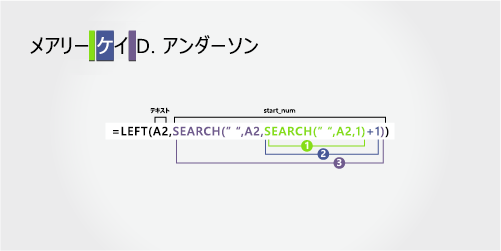
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (5)
-
1 を追加して、最初のスペース (K) の後の文字の位置を取得します。 結果は、スペースの 2 番目のインスタンスの検索を開始する文字数です。 (5 + 1 = 6)
-
手順 2 で見つかった 6 番目の位置 (K) から始まる、A2 内のスペースの 2 番目のインスタンスを検索します。 結果は、テキスト文字列から LEFT が抽出した文字数です。 (9)
-
ミドル ネーム
ミドル ネームは 10 番目の位置 (D) から始まり、12 番目の位置 (3 番目のスペース) で終わります。 この数式では、SEARCH を入れ子にして、スペースの最初、2 番目、および 3 番目のインスタンスを検索します。
数式は、10 番目の位置から 2 文字を中央から抽出します。
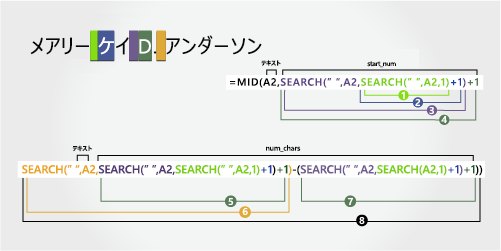
入れ子になった SEARCH 関数を使用して、start_numの値を検索します。
左側の最初の文字から始まる、A2 の最初のスペースの数値位置を検索します。 (5)
-
1 を追加して、最初のスペース (K) の後の文字を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (5 + 1 = 6)
-
手順 2 で見つかった 6 番目の位置 (K) から始まる、A2 内の空間の 2 番目のインスタンスの位置を検索します。 結果は、左から左から抽出された文字数です。 (9)
-
1 を追加して、2 番目のスペース (D) の後の文字を取得します。 結果は、ミドル ネームの開始位置です。 (9 + 1 = 10)
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
2 番目のスペース (D) の後の文字の数値位置を検索します。 結果は、3 番目のスペースの検索を開始する文字数です。 (10)
-
A2 の 3 番目のスペースの数値位置を左から検索します。 結果は、ミドル ネームの終了位置です。 (12)
-
2 番目のスペース (D) の後の文字の数値位置を検索します。 結果は、ミドル ネームの先頭位置です。 (10)
-
手順 6 で見つかった 3 番目のスペースの文字数を取得し、手順 7 で見つかった "D" の文字数を減算します。 結果は、手順 4 で見つかった 10 番目の位置から始まるテキスト文字列から MID が抽出した文字数です。 (12 - 10 = 2)
-
姓
姓は右側から 8 文字で始まります。 この数式では、SEARCH を入れ子にして、5 番目、9 番目、12 番目の位置のスペースの最初、2 番目、および 3 番目のインスタンスを検索します。
数式では、右側から 8 文字が抽出されます。
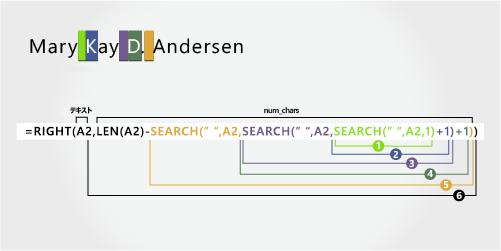
入れ子になった SEARCH 関数と LEN 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (5)
-
1 を追加して、最初のスペース (K) の後の文字を取得します。 結果は、スペースの検索を開始する文字番号です。 (5 + 1 = 6)
-
手順 2 で見つかった 6 番目の位置 (K) から開始して、A2 の 2 番目のスペースを検索します。 (9)
-
1 を追加して、2 番目のスペース (D) の後の文字の位置を取得します。 結果は、ミドル ネームの開始位置です。 (9 + 1 = 10)
-
A2 の 3 番目のスペースの数値位置を左から検索します。 結果は、ミドル ネームの終了位置です。 (12)
-
A2 のテキスト文字列の長さの合計をカウントし、手順 5 で見つかった 3 番目のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (20 - 12 = 8)
この例では、3 部構成の姓を使用します。Barreto de Mattos。 最初のスペースは、名の末尾と姓の先頭を示します。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
Paula Barreto de Mattos |
3 部構成の姓 |
|
数式 |
結果 (名) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (姓) |
|
RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
-
名
最初の名前は、左 (P) の最初の文字で始まり、6 番目の文字 (最初のスペース) で終わります。 数式では、左側から 6 文字が抽出されます。

Search 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
姓
姓は右から 17 文字 (B) で始まり、右側の最初の文字で終わります。 数式では、右側から 17 文字が抽出されます。
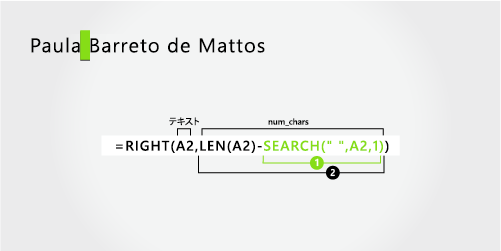
LEN 関数と SEARCH 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
A2 のテキスト文字列の長さの合計をカウントし、手順 1 で見つかった左から最初のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (23 - 6 = 17)
この例では、2 部構成の姓 van Eaton を使用します。 最初のスペースは、名の末尾と姓の先頭を示します。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
James van Eaton |
2 部構成の姓 |
|
数式 |
結果 (名) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (姓) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
-
名
最初の名前は、左 (J) の最初の文字で始まり、8 番目の文字 (最初のスペース) で終わります。 数式では、左側から 6 文字が抽出されます。

SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
姓
姓は右から 9 文字目 (v) で始まり、右側 (n) の最初の文字で終わります。 数式は、フル ネームの右側から 9 文字を抽出します。

LEN 関数と SEARCH 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
A2 のテキスト文字列の長さの合計をカウントし、手順 1 で見つかった左から最初のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (15 - 6 = 9)
この例では、姓の先頭にサフィックスが続きます。 コンマは、姓とサフィックスを名と中間のイニシャルから区切ります。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
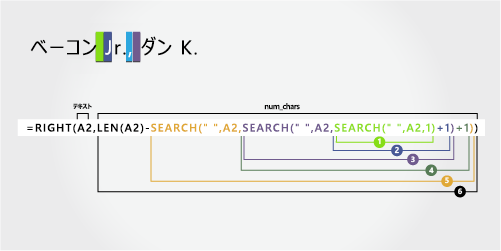
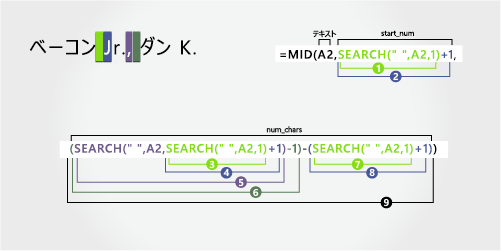
ベーコン Jr.、Dan K. |
姓とサフィックスの先頭にコンマを付けます |
|
数式 |
結果 (名) |
|
'=MID(A2,SEARCH(" ",A2,1)+1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)-SEARCH(" ",A2,1)+1)-SEARCH(" ",A2,1)+1)) |
=MID(A2,SEARCH(" ",A2,1)+1)+1,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)-SEARCH(" ",A2,1)+1)-SEARCH(" ",A2,1)+1)) |
|
数式 |
結果 (中間初期) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,SEARCH(" ",A2,1)+1)+1)) |
|
数式 |
結果 (姓) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (サフィックス) |
|
'=MID(A2,SEARCH(" ", A2,1)+1,(SEARCH(" ",A2,SEARCH(" ",A2,1)+1)-2)-SEARCH(" ",A2,1)) |
=MID(A2,SEARCH(" ", A2,1)+1,(SEARCH(" ",A2,SEARCH(" ",A2,1)+1)-2)-SEARCH(" ",A2,1)) |
-
名
最初の名前は 12 番目の文字 (D) で始まり、15 番目の文字 (3 番目のスペース) で終わります。 数式は、12 番目の位置から 3 文字を抽出します。
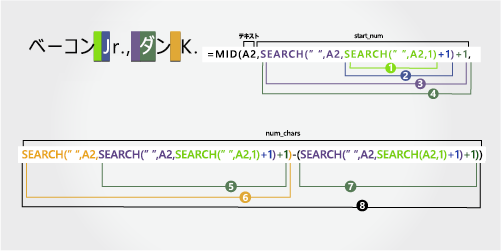
入れ子になった SEARCH 関数を使用して、start_numの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
1 を追加して、最初のスペース (J) の後の文字を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (6 + 1 = 7)
-
手順 2 で見つかった 7 番目の位置 (J) から始まる A2 の 2 番目のスペースを検索します。 (11)
-
1 を追加して、2 番目のスペース (D) の後の文字を取得します。 結果は、名の開始位置です。 (11 + 1 = 12)
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
2 番目のスペース (D) の後の文字の数値位置を検索します。 結果は、3 番目のスペースの検索を開始する文字数です。 (12)
-
A2 の 3 番目のスペースの数値位置を左から検索します。 結果は、名の終了位置です。 (15)
-
2 番目のスペース (D) の後の文字の数値位置を検索します。 結果は、名の先頭位置になります。 (12)
-
手順 6 で見つかった 3 番目のスペースの文字数を取得し、手順 7 で見つかった "D" の文字数を減算します。 結果は、手順 4 で見つかった 12 番目の位置から始まるテキスト文字列から MID が抽出した文字数です。 (15 - 12 = 3)
-
ミドル ネーム
ミドル ネームは、右側の 2 番目の文字 (K) で始まります。 数式は右側から 2 文字を抽出します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
1 を追加して、最初のスペース (J) の後の文字を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (6 + 1 = 7)
-
手順 2 で見つかった 7 番目の位置 (J) から始まる A2 の 2 番目のスペースを検索します。 (11)
-
1 を追加して、2 番目のスペース (D) の後の文字を取得します。 結果は、名の開始位置です。 (11 + 1 = 12)
-
A2 の 3 番目のスペースの数値位置を左から検索します。 結果は、ミドル ネームの終了位置です。 (15)
-
A2 のテキスト文字列の長さの合計をカウントし、手順 5 で見つかった左から 3 番目のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (17 - 15 = 2)
-
姓
姓は左 (B) の最初の文字から始まり、6 文字目 (最初のスペース) で終わります。 そのため、数式は左から 6 文字を抽出します。

SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
サフィックス
サフィックスは、左から 7 文字目 (J) で始まり、左 (.) から 9 文字目で終わります。 数式は、7 文字目から 3 文字を抽出します。
SEARCH 関数を使って、"開始位置" 引数に渡す値を取得します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
1 を追加して、最初のスペース (J) の後の文字を取得します。 結果はサフィックスの開始位置です。 (6 + 1 = 7)
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
1 を追加して、最初のスペース (J) の後の文字の数値位置を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (7)
-
手順 4 で見つかった 7 文字目から始まる、A2 の 2 番目のスペースの数値位置を検索します。 (11)
-
手順 4 で見つかった 2 番目のスペースの文字数から 1 を減算して、"," の文字番号を取得します。 結果はサフィックスの終了位置です。 (11 - 1 = 10)
-
最初のスペースの数値位置を検索します。 (6)
-
最初のスペースを見つけたら、1 を追加して次の文字 (J) を見つけます。手順 3 と 4 でも見つかります。 (7)
-
手順 6 で見つかった "," の文字数を取り、手順 3 と 4 で見つかった "J" の文字数を減算します。 結果は、手順 2 で見つかった 7 番目の位置から始まるテキスト文字列から MID が抽出した文字数です。 (10 - 7 = 3)
この例では、名は文字列の先頭にあり、サフィックスは末尾にあります。例 2 のような数式を使用できます。LEFT 関数を使用して名を抽出し、MID 関数を使用して姓を抽出し、RIGHT 関数を使用してサフィックスを抽出します。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
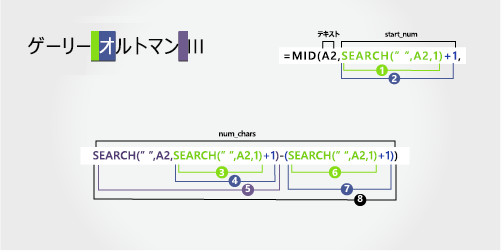
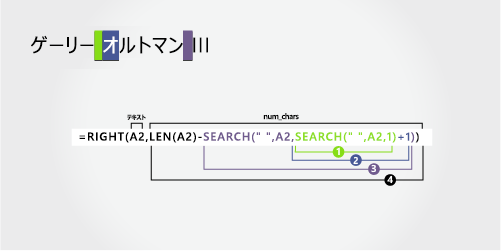
Gary Altman III |
サフィックスを持つ姓と名 |
|
数式 |
結果 (名) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (姓) |
|
'=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,1)+1)-(SEARCH(" ",A2,1)+1)) |
=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,1)+1)-(SEARCH(" ",A2,1)+1)) |
|
数式 |
結果 (サフィックス) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
-
名
最初の名前は、左 (G) の最初の文字から始まり、5 番目の文字 (最初のスペース) で終わります。 したがって、数式はフル ネームの左側から 5 文字を抽出します。

A2 の最初のスペースの左側から始まる数値の位置を検索します。 (5)
-
姓
姓は、左 (A) の 6 文字目から始まり、11 文字目 (2 番目のスペース) で終わります。 この数式では、SEARCH を入れ子にしてスペースの位置を検索します。
数式は、6 番目の文字から始まる中央から 6 文字を抽出します。
SEARCH 関数を使って、"開始位置" 引数に渡す値を取得します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (5)
-
1 を追加して、最初のスペース (A) の後の文字の位置を取得します。 結果は、姓の開始位置です。 (5 + 1 = 6)
ネストされた SEARCH 関数を使って、"文字数" 引数に渡す値を取得します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (5)
-
1 を追加して、最初のスペース (A) の後の文字の位置を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (5 + 1 = 6)
-
手順 4 で見つかった 6 番目の文字から始まる、A2 の 2 番目のスペースの数値位置を検索します。 この文字番号は、姓の終了位置です。 (12)
-
最初のスペースの数値位置を検索します。 (5)
-
1 を追加して、最初のスペース (A) の後の文字の数値位置を検索します。手順 3 と 4 でも見つかります。 (6)
-
手順 5 で見つかった 2 番目のスペースの文字番号を取り、手順 6 と 7 で見つかった "A" の文字数を減算します。 結果は、手順 2 で見つかった 6 番目の位置から始まるテキスト文字列から MID が抽出した文字数です。 (12 - 6 = 6)
-
サフィックス
サフィックスは、右側から 3 文字で始まります。 この数式では、SEARCH を入れ子にしてスペースの位置を検索します。
入れ子になった SEARCH 関数と LEN 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (5)
-
1 を追加して、最初のスペース (A) の後の文字を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (5 + 1 = 6)
-
手順 2 で見つかった、6 番目の位置 (A) から始まる A2 の 2 番目のスペースを検索します。 (12)
-
A2 のテキスト文字列の合計長をカウントし、手順 3 で見つかった左から 2 番目のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (15 - 12 = 3)
この例では、完全な名前の前にプレフィックスが付き、例 2 のような数式を使用します。MID 関数を使用して名を抽出し、RIGHT 関数を使用して姓を抽出します。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
Ryan Ihrig 氏 |
プレフィックス付き |
|
数式 |
結果 (名) |
|
'=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,1)+1)-(SEARCH(" ",A2,1)+1)) |
=MID(A2,SEARCH(" ",A2,1)+1,SEARCH(" ",A2,1)+1)-(SEARCH(" ",A2,1)+1)) |
|
数式 |
結果 (姓) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,SEARCH(" ",A2,1)+1)) |
-
名
最初の名前は、左 (R) の 5 文字目から始まり、9 番目の文字 (2 番目のスペース) で終わります。 数式は SEARCH を入れ子にして、スペースの位置を検索します。 5 番目の位置から 4 文字を抽出します。
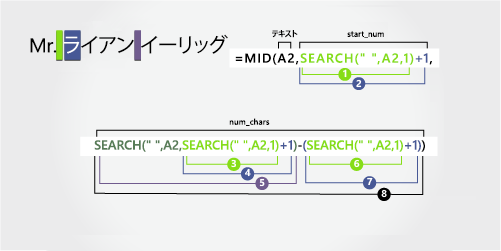
SEARCH 関数を使用して、start_numの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (4)
-
1 を追加して、最初のスペース (R) の後の文字の位置を取得します。 結果は、名の開始位置です。 (4 + 1 = 5)
入れ子になった SEARCH 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (4)
-
1 を追加して、最初のスペース (R) の後の文字の位置を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (4 + 1 = 5)
-
手順 3 と 4 の 5 番目の文字から始まる、A2 の 2 番目のスペースの数値位置を検索します。 この文字番号は、名の終了位置です。 (9)
-
最初のスペースを検索します。 (4)
-
1 を追加して、最初のスペース (R) の後の文字の数値位置を検索します。手順 3 と 4 でも見つかります。 (5)
-
手順 5 で見つかった 2 番目のスペースの文字数を取得し、手順 6 と 7 で見つかった "R" の文字数を減算します。 結果は、手順 2 で見つかった 5 番目の位置から始まる、テキスト文字列から MID が抽出した文字数です。 (9 - 5 = 4)
-
姓
姓は右側から 5 文字で始まります。 この数式では、SEARCH を入れ子にしてスペースの位置を検索します。
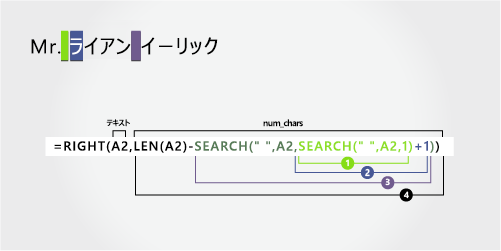
入れ子になった SEARCH 関数と LEN 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (4)
-
1 を追加して、最初のスペース (R) の後の文字の位置を取得します。 結果は、2 番目のスペースの検索を開始する文字数です。 (4 + 1 = 5)
-
手順 2 で見つかった、5 番目の位置 (R) から始まる A2 の 2 番目のスペースを検索します。 (9)
-
A2 のテキスト文字列の合計長をカウントし、手順 3 で見つかった左から 2 番目のスペースまでの文字数を減算します。 結果は、フル ネームの右側から抽出される文字数です。 (14 - 9 = 5)
この例では、ハイフネーションされた姓を使用します。 各名前コンポーネントはスペースで区切られます。
テーブル内のセルをコピーし、セル A1 の Excel ワークシートに貼り付けます。 左側に表示される数式は参照用に表示され、Excel は右側の数式を適切な結果に自動的に変換します。
ヒント ワークシートにデータを貼り付ける前に、列 A と B の列幅を 250 に設定します。
|
名前の例 |
説明 |
|
Julie Taft-Rider |
ハイフンで区切られた姓 |
|
数式 |
結果 (名) |
|
'=LEFT(A2, SEARCH(" ",A2,1)) |
=LEFT(A2, SEARCH(" ",A2,1)) |
|
数式 |
結果 (姓) |
|
'=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
=RIGHT(A2,LEN(A2)-SEARCH(" ",A2,1)) |
-
名
最初の名前は、左から最初の文字から始まり、6 番目の位置 (最初のスペース) で終わります。 数式では、左側から 6 文字が抽出されます。

SEARCH 関数を使用して、num_charsの値を検索します。
A2 の最初のスペースの左側から始まる数値の位置を検索します。 (6)
-
姓
姓全体が右から 10 文字 (T) で始まり、右側 (r) の最初の文字で終わります。
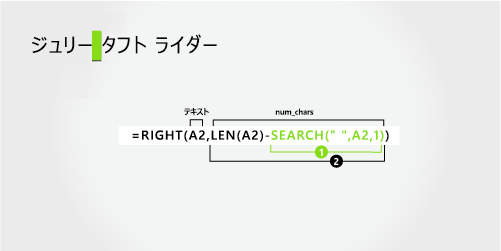
LEN 関数と SEARCH 関数を使用して、num_charsの値を検索します。
左側の最初の文字から始まる、A2 内のスペースの数値位置を検索します。 (6)
-
抽出するテキスト文字列の長さの合計をカウントし、手順 1 で見つかった左から最初のスペースまでの文字数を減算します。 (16 - 6 = 10)









