
最初に Power Pivot を使用する方法を学習するとき、ほとんどのユーザーは、実際のパワーが何らかの方法で結果を集計または計算することを発見します。 データに数値を含む列がある場合は、ピボットテーブルまたは Power View フィールド リストで選択することで簡単に集計できます。 自然に、数値であるため、自動的に集計、平均、カウント、または選択した集計の種類が自動的に計算されます。 これは暗黙的なメジャーと呼ばれます。 暗黙的なメジャーは、迅速で簡単な集計には最適ですが、制限があり、これらの制限は、ほとんどの場合、明示的な メジャー と 計算列で克服できます。
最初に、計算列を使用して Product という名前のテーブル内の各行に新しいテキスト値を追加する例を見てみましょう。 Product テーブルの各行には、販売する各製品に関するすべての種類の情報が含まれています。 製品名、色、サイズ、ディーラー価格などの列があります。 ProductCategoryName 列を含む Product Category という名前の別の関連テーブルがあります。 必要なのは、Product テーブル内の各製品について、製品カテゴリ テーブルの製品カテゴリ名を含めます。 Product テーブルでは、次のような Product Category という名前の計算列を作成できます。
![[計算済み製品カテゴリ] 列](https://support.content.office.net/ja-jp/media/46881c2d-5129-48ee-9718-0d67b503e4fe.jpg)
新しい Product Category 数式では 、RELATED DAX 関数を使用して、関連する Product Category テーブルの ProductCategoryName 列から値を取得し、Product テーブルに各製品 (各行) の値を入力します。
これはすぐれた例であり、集計列を使って固定値を行ごとに追加し、ピボットテーブルの行、列、フィルター領域または Power View レポートで使えるようにする方法を示しています。
製品カテゴリの利益率を計算する別の例を作成しましょう。 これは、多くのチュートリアルでも一般的なシナリオです。 データ モデルには、トランザクション データを含む Sales テーブルがあり、Sales テーブルと製品カテゴリ テーブルの間にリレーションシップがあります。 Sales テーブルには、売上金額を含む列と、コストを含む別の列があります。
次のように、売上高の列の値から COGS 列の値を差し引いて、利益金額を行ごとに計算する集計列を作成できます。
![Power Pivot テーブルの [利益] 列](https://support.content.office.net/ja-jp/media/11106e9d-4f60-4054-9a24-2b5ba5dc1097.jpg)
ここでピボットテーブルを作成して製品カテゴリ フィールドを列の領域に、新しい利益フィールドを値の領域にドラッグできます (PowerPivot のテーブルの列は、ピボットテーブルのフィールド一覧のフィールドです)。 結果は、合計利益という名前の暗黙的メジャーです。 これは、さまざまな製品カテゴリごとに利益列の値を集計した金額です。 結果は次のように表示されます。
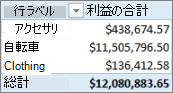
この場合、利益は値のフィールドとしてのみ意味があります。 利益を列の領域に配置すると、ピボットテーブルは次のようになります。
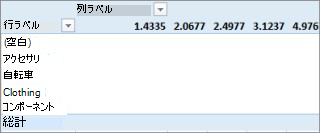
利益フィールドは、列、行、フィルターの領域に配置しても、有用な情報を提供しません。 値の領域の集計値としてのみ意味があります。
これまでに、利益という名前の列を作成して、売上テーブルの行ごとに利益率を計算しました。 次に、利益をピボットテーブルの値の領域に追加すると、暗黙的メジャーが自動的に作成され、結果が製品カテゴリごとに計算されました。 製品カテゴリの利益を実際には 2 回計算したのではないかと疑問に思った人は正解です。 最初に売上テーブルの行ごとに利益を計算し、利益を値の領域に追加して、製品カテゴリごとに集計しました。 利益の集計列を作成する必要はなかったのではないかと思った人も正解です。 では、集計列を作成せずに利益を計算する方法はあるのでしょうか。
利益は、実際には明示的メジャーとして、さらに適切に計算されます。
とりあえず、利益の集計列は売上テーブルに残し、製品カテゴリはピボットテーブルの列に、利益は値に残して、結果を比較することにします。
売上テーブルの計算領域に、名前の競合を避けて、総利益という名前のメジャーを作成します。 最終的には、これまでと同じ結果になりますが、利益の集計列はできません。
最初に、売上テーブルで売上高の列を選び、[オート SUM] をクリックして売上高の合計の示的なメジャーを作成します。 明示的メジャーは、Power Pivot のテーブルの計算領域に作成するものであることに注意してください。 COGS 列も同様に操作します。 名前は売上高の合計と COGS の合計に変更して、識別しやすくします。
![PowerPivot の [オート SUM] ボタン](https://support.content.office.net/ja-jp/media/06aedb02-cf0e-4a5c-a440-97cd7aceb10c.jpg)
次の数式を使って、別のメジャーを作成します。
総利益:=[ 売上高の合計] - [ COGS の合計]
注: この数式は、総利益:=SUM([売上高]) - SUM([COGS]) とすることもできますが、売上高の合計と COGS の合計という別個のメジャーを作成すると、ピボットテーブルでもそれを使用でき、あらゆる種類のその他のメジャーの数式で引数としてそれを使用できるようになります。
総利益の新しいメジャーの書式を通貨に変更した後で、ピボットテーブルに追加できます。
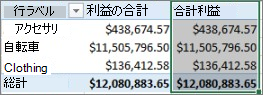
新しい Total Profit メジャーは、Profit 計算列を作成してから VALUES に配置するのと同じ結果を返すのを確認できます。 その違いは、Total Profit メジャーの方がはるかに効率的で、データ モデルがクリーンで無駄が少なくなるためです。これは、その時点で計算しているため、ピボットテーブルに対して選択したフィールドに対してのみです。 結局のところ、Profit 計算列は本当に必要ありません。
この最後の部分が重要なのはなぜですか? 計算列はデータ モデルにデータを追加し、データはメモリを占有します。 データ モデルを更新する場合、Profit 列のすべての値を再計算するために、処理リソースも必要です。 このようなリソースは、製品カテゴリ、地域、日付など、ピボットテーブルで Profit が必要なフィールドを選択するときに利益を計算する必要があるため、実際には必要ありません。
別の例を挙げてみましょう。 この例では集計列で結果が作成され、その結果は一見正しいようですが….
この例では、売上金額を総売上のパーセンテージとして計算します。 次のように、売上 (%) という名前の集計列を売上テーブルに作成します。
![[計算済み売り上げの %] 列](https://support.content.office.net/ja-jp/media/4654d626-2e7c-4c68-8a39-7658445f7137.jpg)
この数式では、売上テーブルの行ごとに、売上高列の金額が、売上高列のすべての金額の合計で割られます。
ピボットテーブルを作成し、製品カテゴリを列に追加して、新しい売上 (%) 列を選んで値に配置すると、製品カテゴリごとに売上 (%) の合計が計算されます。
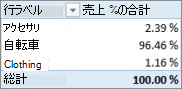
よろしいでしょうか。 ここまでは正しいように見えます。 しかし、スライサーを追加してみましょう。 カレンダー年度を追加して、年を選びます。 この場合は 2007 を選びます。 次のような結果になります。
![ピボットテーブルの [売り上げの % の合計] の正しくない結果](https://support.content.office.net/ja-jp/media/e9ecea1f-a3f1-43c8-9d5f-51177e88e41d.jpg)
一見すると、これは正しく表示される場合があります。 ただし、2007 年の各製品カテゴリの売上合計の割合を知りたいので、割合は本当に合計 100% である必要があります。 それでは、何が間違っていたのでしょうか?
売上 (%) 列では、売上高列の値を売上高列のすべての値の合計で割って行ごとに割合を計算します。 集計列の値は固定です。 テーブルの行ごとの、変更できない結果です。 売上 (%) をピボットテーブルに追加すると、売上高列のすべての値の合計として集計されます。 売上 (%) 列のすべての値の合計は、常に 100% です。
ヒント: DAX 数式のコンテキストを必ず読んでください。 行レベルのコンテキストおよびフィルター コンテキスト (ここで説明していること) についてよく理解できます。
売上 (%) 集計列は、役に立たないので削除できます。 その代わりにメジャーを作成すると、どのフィルターやスライサーを適用しても、総売上の割合は正しく計算されます。
前に作成した売上高合計のメジャーは、売上高列を単純に合計したものでした。 総利益のメジャーでは、この列を引数として使いましたが、新しい集計フィールドでも引数として再び使います。
ヒント: 売上高の合計や COGS の合計などの明示的メジャーを作成すると、ピボットテーブルやレポートでそれ自体が役立つだけでなく、結果が引数として必要となるときは、その他のメジャーで引数としても役立ちます。 これで、数式はさらに効率的になって読みやすくなります。 これは適切なデータ モデリングの方法です。
次の数式を使って、新しいメジャーを作成します。
売上の合計 (%):=([売上高の合計]) / CALCULATE([売上高の合計], ALLSELECTED())
この数式では、売上高の合計の結果を売上高の合計で割り、列や行のフィルターのうちピボットテーブルで定義されているものを適用します。
ヒント: DAX リファレンスの CALCULATE 関数と ALLSELECTED 関数については、必ずお読みください。
新しい売上の合計 (%) をピボットテーブルに追加すると、次のようになります。
![ピボットテーブルの [売り上げの % の合計] の正しい結果](https://support.content.office.net/ja-jp/media/19d4f53f-1760-48e3-977f-a5320b3db2b0.jpg)
適切になったようです。 製品カテゴリごとの売上の合計 (%) は、2007 年の総売上の割合として計算されます。 カレンダー年度スライサーで別の年を選んだり、複数年を選んだりした場合、製品カテゴリのパーセンテージは新しくなりますが、総計は 100% になります。 別のスライサーやフィルターを追加することもできます。 どのスライサーやフィルターを適用しても、売上の合計 (%) メジャーでは、常に総売上のパーセンテージが算出されます。 メジャーを使うと、結果は常に、列と行のフィールド、および適用されるフィルターやスライサーによって決まるコンテキストに従って計算されます。 これがメジャーの機能です。
次のガイドラインは、集計列とメジャーのどちらが特定の計算ニーズに適しているかを判断するときに役立ちます。
集計列を使う
-
新しいデータをピボットテーブルの ROWS、COLUMNS、または FILTERS に表示する場合、または Power View 視覚エフェクトの AXIS、LEGEND、または TILE BY に表示する場合は、計算列を使用する必要があります。 データの通常の列と同じように、集計列はどの領域でもフィールドとして使用でき、集計列が数値である場合は、値でも集計できます。
-
新しいデータを行の固定値にする場合。 たとえば、日付テーブルがあって日付の列が含まれており、別の列に月の番号のみを含める必要があるとします。 集計列を作成すると、日付列の日付から月の番号のみを計算できます。 たとえば、=MONTH(‘日付’[日付]) というようにします。
-
テーブルの行ごとにテキスト値を追加する場合は、集計列を使います。 テキスト値を含むフィールドは、値で集計できません。 たとえば、=FORMAT('日付'[日付],"mmmm") では、日付テーブルの日付列の日付ごとに、月の名前を取得できます。
メジャーを使う
-
計算の結果が、ピボットテーブルで選んだその他のフィールドに常に依存する場合。
-
ある種のフィルターに基づいてカウントを計算したり、前年比や分散を計算したりというように、より複雑な計算を行う必要がある場合は、集計フィールドを使います。
-
ブックのサイズを最小限にしてパフォーマンスを最大にする場合は、可能な限り多くの計算をメジャーとして作成します。 多くの場合は、すべての計算をメジャーにすると、ブックのサイズが著しく小さくなり、更新時間を短縮できます。
利益列で行ったように集計列を作成して、ピボットテーブルやレポートで集計することに、まったく問題がないことに注意してください。 実際にこれは本当に適切であり、簡単に習得して独自の計算を作成できるようになります。 Power Pivot の非常に強力なこの 2 つの機能を深く理解するようになると、できる限り効率的で正確なデータ モデルを作成できるようになります。 ここで習得したことが役立つことを願っています。 他にも、本当に役に立つ、すばらしいリソースがあります。 「DAX の数式のコンテキスト」、「PowerPivot での集計」、「DAX リソース センター」は、そのほんの数例にすぎません。 また、もう少し高度で、会計と財務の専門家向けですが、 Excel の Microsoft Power Pivot を使用した損益データ モデリングと分析 のサンプルには、優れたデータ モデリングと数式の例が読み込まれています。









