
Artikel ini menguraikan sintaks rumus dan penggunaan fungsi LINEST di Microsoft Excel.
Deskripsi
Fungsi LINEST menghitung statistik untuk sebuah garis dengan menggunakan metode "kuadrat terkecil" untuk menghitung garis lurus yang paling cocok dengan data Anda, dan kemudian mengembalikan array yang menguraikan garis tersebut. Anda juga dapat mengombinasikan LINEST dengan fungsi-fungsi lainnya untuk menghitung statistik untuk tipe model lain yang linear dalam parameter yang tidak diketahui, termasuk polinomial, logaritmik, eksponensial, dan serangkaian pangkat. Karena fungsi ini mengembalikan sebuah array nilai, maka harus dimasukkan sebagai rumus array. Petunjuk mengikuti contoh-contoh dalam artikel ini.
Persamaan untuk garis adalah:
y = mx + b
–atau–
y = m1x1 + m2x2 + ... + b
jika ada beberapa rentang nilai x, di mana nilai y tidak bebasnya adalah fungsi nilai x bebas. Nilai m adalah koefisien yang berkaitan dengan setia nilai x, dan b adalah nilai konstanta. Perhatikan y, x, dan m bisa menjadi vektor. Array yang dikembalikan oleh fungsi LINEST adalah {mn,mn-1,...,m1,b}. LINEST juga bisa mengembalikan regresi statistik tambahan.
Sintaks
LINEST(known_y's, [known_x's], [const], [stats])
Sintaks fungsi LINEST memiliki argumen berikut:
Sintaks
-
known_y's Diperlukan. Serangkaian nilai y yang sudah Anda ketahui dalam hubungan y = mx + b.
-
Jika rentang known_y's berada di dalam kolom tunggal, maka setiap kolom known_x's diterjemahkan sebagai variabel terpisah.
-
Jika rentang known_y's terdapat di dalam kolom tunggal, maka setiap kolom known_x's diterjemahkan sebagai variabel terpisah.
-
-
known_x's Opsional. Serangkaian nilai x yang mungkin sudah Anda ketahui dalam hubungan y = mx + b.
-
Rentang known_x's dapat mencakup satu atau lebih variabel. Jika hanya satu variabel yang digunakan, maka known_y's dan known_x's dapat berupa rentang berbentuk apa saja, selama memiliki dimensi yang sama. Jika lebih dari satu variabel yang digunakan, maka known_y's harus berupa vektor (yaitu, rentang dengan tinggi satu baris atau lebar satu kolom).
-
Jika known_x's dikosongkan, maka diasumsikan sebagai array {1,2,3,...} yang memiliki ukuran sama dengan known_y's.
-
-
const Opsional. Sebuah nilai logika yang menentukan apakah memaksakan konstanta b sama dengan 0.
-
Jika const TRUE atau dikosongkan, maka b dihitung secara normal.
-
Jika const FALSE, maka b diatur agar sama dengan 0 dan nilai m disesuaikan agar pas dengan y = mx.
-
-
stats Opsional. Nilai logika yang menentukan apakah akan mengembalikan regresi statistik tambahan.
-
Jika stats TRUE, LINEST mengembalikan statistik regresi tambahan; sebagai hasilnya, array yang dikembalikan adalah {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
-
Jika stats FALSE atau dikosongkan, maka LINEST hanya mengembalikan koefisien m dan konstanta b.
Regresi statistik tambahannya adalah sebagai berikut.
-
|
Statistik |
Deskripsi |
|---|---|
|
se1,se2,...,sen |
Nilai kesalahan standar untuk koefisien m1,m2,...,mn. |
|
seb |
Nilai kesalahan standar untuk konstanta b (seb = #N/A ketika const adalah FALSE). |
|
r2 |
Koefisien determinasi. Membandingkan nilai y perkiraan dan aktual, dan rentang dalam nilai dari 0 sampai 1. Jika 1, maka ada korelasi sempurna dalam sampel — tidak ada perbedaan antara perkiraan nilai y dan nilai y aktual. Pada ekstrem lain, jika koefisien determinasi 0, maka persamaan regresi tidak membantu dalam memperkirakan nilai y. Untuk informasi tentang carapenghitungan 2 , lihat "Keterangan," selanjutnya dalam topik ini. |
|
sey |
Nilai kesalahan standar untuk perkiraan y. |
|
URL |
Statistik F, atau nilai F yang diobservasi. Gunakan statistik F untuk menentukan apakah hubungan yang diobservasi antara variabel tidak bebas dan variabel bebas terjadi secara kebetulan. |
|
df |
Derajat kebebasan. Gunakan derajat kebebasan untuk membantu Anda menemukan nilai kritis F dalam tabel statistik. Bandingkan nilai yang Anda temukan dalam tabel dengan statistik F yang dikembalikan oleh LINEST untuk menentukan tingkat kepercayaan terhadap model tersebut. Untuk informasi tentang bagaimana df dihitung, lihat "Keterangan," di bagian berikutnya dalam topik ini. Contoh 4 menunjukkan penggunaan F dan df. |
|
ssreg |
Regresi jumlah kuadrat. |
|
ssresid |
Residual jumlah kuadrat. Untuk informasi tentang bagaimana ssreg dan ssresid dihitung, lihat "Keterangan," di bagian berikutnya dalam topik ini. |
Ilustrasi berikut ini menunjukkan urutan tempat statistik regresi tambahan dikembalikan.

Keterangan
-
Anda dapat menguraikan garis lurus dengan kemiringan dan garis potong y:
Kelopak (m): Untuk menemukan kelereng garis, sering ditulis sebagai m, ambil dua titik pada garis, (x1,y1) dan (x2,y2); kelopak sama dengan (y2 - y1)/(x2 - x1).
Potong y (b): Garis potong y, sering ditulis sebagai b, adalah nilai y pada titik di mana garis melewati sumbu y.
Persamaan garis lurus adalah y = mx + b. Setelah mengetahui nilai m dan b, Anda dapat menghitung titik pada garis dengan memasukkan nilai y atau x ke dalam persamaan itu. Anda juga dapat menggunakan fungsi TREND.
-
Ketika Anda hanya punya satu variabel data bebas x, Anda bisa mendapatkan nilai kemiringan dan garis potong y secara langsung dengan menggunakan rumus berikut ini:
Lereng: =INDEX(LINEST(known_y,known_x's),1)
Perpotongan Y: =INDEX(LINEST(known_y,known_x's),2)
-
Keakuratan garis dihitung dengan fungsi LINEST tergantung dari derajat penyebaran dalam data Anda. Semakin linear data, semakin akurat model LINEST. LINEST menggunakan metode kuadrat terkecil untuk menentukan yang paling cocok untuk data. Ketika Anda hanya punya satu variabel bebas x, maka perhitungan untuk m dan b didasarkan pada rumus berikut ini:
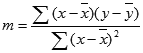
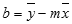
di mana x dan y adalah sarana sampel; yaitu, x = AVERAGE(known x's) dan y = AVERAGE(known_y's).
-
Fungsi line- and curve-fitting LINEST dan LOGEST dapat menghitung garis lurus atau kurva eksponensial terbaik yang sesuai dengan data Anda. Namun, Anda harus memutuskan mana dari dua hasil yang paling pas dengan data Anda. Anda dapat menghitung TREND(known_y,known_x) untuk garis lurus, atau GROWTH(known_y, known_x) untuk kurva eksponensial. Fungsi ini, tanpa argumen new_x , mengembalikan array nilai y yang diprediksi di sepanjang garis atau kurva tersebut pada titik data aktual Anda. Anda kemudian dapat membandingkan nilai yang diprediksi dengan nilai aktual. Anda mungkin ingin membuat bagan keduanya untuk perbandingan visual.
-
Dalam analisis regresi, untuk setiap titik Excel menghitung selisih kuadrat antara nilai perkiraan y dengan nilai aktual y titik tersebut. Jumlah selisih kuadrat ini disebut jumlah residual kuadrat, ssresid. Kemudian Excel menghitung jumlah kuadrat total, sstotal. Ketika argumen const = TRUE atau dikosongkan, jumlah kuadrat total adalah jumlah selisih kuadrat antara nilai aktual y dengan nilai rata-rata y. Ketika argumen const = FALSE, jumlah total kuadrat adalah jumlah kuadrat nilai aktual y (tanpa mengurangi nilai rata-rata y dari masing-masing nilai individu y). Lalu regresi jumlah kuadrat, ssreg, dapat dicari dari: ssreg = sstotal - ssresid. Semakin kecil jumlah sisa kuadrat, dibandingkan dengan jumlah total kuadrat, semakin besar nilai koefisien determinasi, r2, yang merupakan indikator seberapa baik persamaan yang dihasilkan dari analisis regresi menjelaskan hubungan di antara variabel. Nilai r2 sama dengan ssreg/sstotal.
-
Dalam beberapa kasus, satu atau lebih kolom X (dengan asumsi Y dan X berada di dalam kolom) mungkin tidak memiliki nilai ramalan dengan kehadiran kolom-kolom X lainnya. Dengan kata lain, menghilangkan satu atau lebih kolom X mungkin akan mengarah ke nilai ramalan Y yang sama akuratnya. Jika demikian, kolom-kolom X berlebihan ini tidak boleh ditulisi model regresi. Fenomena ini disebut “kolinearitas” karena kolom X yang berlebihan dapat diekspresikan sebagai jumlah kelipatan kolom-kolom X yang tidak berlebihan. Fungsi LINEST memeriksa apakah ada kolinearitas dan menghapus kolom-kolom X berlebihan dari model regresi saat fungsi itu mengenalinya. Kolom-kolom X yang dihapus dapat dikenali dalam keluaran LINEST sebagai memiliki koefisien 0 di samping nilai se 0. Jika satu atau lebih kolom dihapus sebagai berlebihan, df terpengaruh karena df tergantung dari jumlah kolom X yang benar-benar digunakan untuk tujuan peramalan. Untuk detail tentang komputasi df, lihat Contoh 4. Jika df berubah karena kolom-kolom X yang berlebihan dihapus, nilai sey dan F juga terpengaruh. Kolinearitas seharusnya relatif jarang pada praktiknya. Akan tetapi, ada satu kasus saat kejadian itu kemungkinan besar muncul, yaitu ketika beberapa kolom X hanya berisi nilai 0 dan 1 sebagai indikator apakah subyek yang ada dalam sebuah percobaan tergabung dengan kelompok tertentu atau bukan. Jika const = TRUE atau dikosongkan, maka fungsi LINEST secara efektif menyisipkan sebuah kolom X tambahan dari semua nilai 1 untuk meniru potongan tersebut. Jika Anda memiliki kolom berisi angka 1 untuk setiap subyek jika laki-laki, atau 0 jika bukan, dan Anda juga punya kolom berisi angka 1 untuk setiap subyek jika perempuan, atau 0 jika bukan, maka kolom terakhir ini berlebihan karena entri di dalamnya bisa didapat dari mengurangkan entri dalam kolom "indikator laki-laki" dari entri dalam kolom tambahan yang berisi semua nilai 1 yang ditambahkan oleh fungsi LINEST.
-
Nilai df dihitung sebagai berikut, ketika tidak ada kolom X yang dihapus dari model karena kolinearitas: jika ada kolom kknown_x’s dan const = TRUE atau dikosongkan, maka df = n – k – 1. Jika const = FALSE, maka df = n - k. Dalam kedua kasus tersebut, setiap kolom X yang dihapus karena kolinearitas meningkatkan nilai df dengan menambah 1.
-
Saat memasukkan konstanta array (seperti known_x's) sebagai sebuah argumen, gunakan koma untuk memisahkan nilai yang ada di dalam baris yang sama dan titik koma untuk memisahkan baris. Karakter pemisah mungkin berbeda tergantung dari pengaturan regional Anda.
-
Perhatikan bahwa nilai y yang diramalkan oleh persamaan regresi mungkin tidak valid jika berada di luar rentang nilai y yang Anda gunakan untuk menentukan persamaannya.
-
Alogaritme pokok yang digunakan dalam fungsi-fungsi LINEST berbeda dengan algoritme pokok yang digunakan dalam fungsi SLOPE dan INTERCEPT. Perbedaan antara algoritma ini dapat mengarah ke hasil yang berbeda ketika data tidak ditentukan dan kolinear. Misalnya, jika titik data argumen known_y's adalah 0 dan titik data argumen known_x's adalah 1:
-
LINEST mengembalikan nilai 0. Alogaritme fungsi LINEST dirancang untuk mengembalikan hasil yang masuk akal untuk data kolinear, dan dalam hal ini, setidaknya satu jawaban dapat ditemukan.
-
SLOPE dan INTERCEPT mengembalikan #DIV/0! . Algoritma fungsi SLOPE dan INTERCEPT dirancang untuk mencari hanya satu jawaban, dan dalam hal ini bisa ada lebih dari satu jawaban.
-
-
Di samping menggunakan LOGEST untuk menghitung statistik untuk berbagai tipe regresi lainnya, Anda dapat menggunakan LINEST untuk menghitung rentang regresi jenis lain dengan memasukkan fungsi variabel x dan y sebagaimana rangkaian x dan y untuk LINEST. Misalnya, rumus berikut ini:
=LINEST(yvalues, xvalues^COLUMN($A:$C))
bekerja ketika Anda memiliki kolom tunggal berisi nilai y dan kolom tunggal untuk nilai x untuk menghitung kubik (polinomial orde 3) aproksimasi dari bentuk:
y = m1*x + m2*x^2 + m3*x^3 + b
Anda dapat menyesuaikan rumus ini untuk menghitung regresi jenis lain, tapi dalam beberapa kasus rumus ini membutuhkan penyesuaian nilai keluaran dan statistik lainnya.
-
Nilai uji F yang dikembalikan oleh fungsi LINEST berbeda dari nilai uji F yang dikembalikan oleh fungsi FTEST. LINEST mengembalikan statistik F, sedangkan FTEST mengembalikan probabilitas.
Contoh
Contoh 1 - Kemiringan dan Titik Potong Y
Salin contoh data di dalam tabel berikut ini dan tempel ke dalam sel A1 lembar kerja Excel yang baru. Agar rumus menunjukkan hasil, pilih datanya, tekan F2, lalu tekan Enter. Jika perlu, Anda bisa menyesuaikan lebar kolom untuk melihat semua data.
|
Known y |
Known x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Hasil (kemiringan) |
Hasil (titik potong y) |
|
2 |
1 |
|
Rumus (rumus array dalam sel A7:B7) |
|
|
=LINEST(A2:A5,B2:B5,,FALSE) |
Contoh 2 - Regresi Linear Sederhana
Salin contoh data di dalam tabel berikut ini dan tempel ke dalam sel A1 lembar kerja Excel yang baru. Agar rumus menunjukkan hasil, pilih datanya, tekan F2, lalu tekan Enter. Jika perlu, Anda bisa menyesuaikan lebar kolom untuk melihat semua data.
|
Bulan |
Penjualan |
|---|---|
|
1 |
$3.100 |
|
2 |
$4.500 |
|
3 |
$4.400 |
|
4 |
$5.400 |
|
5 |
$7.500 |
|
6 |
$8.100 |
|
Rumus |
Hasil |
|
=SUM(LINEST(B1:B6, A1:A6)*{9,1}) |
$11.000 |
|
Menghitung perkiraan penjualan dalam bulan kesembilan, berdasarkan penjualan pada bulan 1 hingga 6. |
Contoh 3 - Regresi Linear Berganda
Salin contoh data di dalam tabel berikut ini dan tempel ke dalam sel A1 lembar kerja Excel yang baru. Agar rumus menunjukkan hasil, pilih datanya, tekan F2, lalu tekan Enter. Jika perlu, Anda bisa menyesuaikan lebar kolom untuk melihat semua data.
|
Luas lantai (x1) |
Kantor (x2) |
Pintu masuk (x3) |
Umur (x4) |
Nilai taksir (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
$142.000 |
|
2333 |
2 |
2 |
1.2 |
$144.000 |
|
2356 |
3 |
1,5 |
33 |
$151.000 |
|
2379 |
3 |
2 |
43 |
$150.000 |
|
2402 |
2 |
3 |
53 |
$139.000 |
|
2425 |
4 |
2 |
23 |
$169.000 |
|
2448 |
2 |
1,5 |
99 |
$126.000 |
|
2471 |
2 |
2 |
34 |
$142.900 |
|
2494 |
3 |
3 |
23 |
$163.000 |
|
2517 |
4 |
4 |
55 |
$169.000 |
|
2540 |
2 |
3 |
22 |
$149.000 |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Rumus (rumus array dinamis yang dimasukkan di A19) |
||||
|
=LINEST(E2:E12,A2:D12,TRUE,TRUE) |
Contoh 4 - Menggunakan Statistik F dan r2
Dalam contoh sebelumnya, koefisien determinasi, atau r2, adalah 0,99675 (lihat sel A17 dalam output untuk LINEST), yang akan menunjukkan hubungan yang kuat antara variabel independen dan harga jual. Anda dapat menggunakan statistik F untuk menentukan apakah hasil-hasil ini, dengan nilai r2 yang begitu tinggi, terjadi karena kebetulan.
Untuk sementara, kita asumsikan tidak ada hubungan di antara variabel-variabelnya, dan Anda telah mengambil sampel langka berupa 11 gedung perkantoran yang mengakibatkan analisis statistik menunjukkan hubungan yang kuat. Istilah "Alpha" digunakan untuk probabilitas kesalahan menyimpulkan bahwa ada hubungan.
Nilai F dan df dalam output dari fungsi LINEST dapat digunakan untuk menilai kemungkinan nilai F yang lebih tinggi yang terjadi secara kebetulan. F dapat dibandingkan dengan nilai kritis dalam tabel distribusi F yang diterbitkan atau fungsi FDIST di Excel dapat digunakan untuk menghitung probabilitas nilai F yang lebih besar yang terjadi secara kebetulan. Distribusi F yang sesuai memiliki v1 dan v2 derajat kebebasan. Jika n adalah jumlah titik data dan const = TRUE atau dihilangkan, maka v1 = n – df – 1 dan v2 = df. (Jika const = FALSE, maka v1 = n – df dan v2 = df.) Fungsi FDIST — dengan sintaks FDIST(F,v1,v2) — akan mengembalikan probabilitas nilai F yang lebih tinggi yang terjadi secara kebetulan. Dalam contoh ini, df = 6 (sel B18) dan F = 459,753674 (sel A18).
Dengan asumsi nilai Alpha 0,05, v1 = 11 – 6 – 1 = 4 dan v2 = 6, tingkat kritis F adalah 4,53. Karena F = 459,753674 jauh lebih tinggi dari 4,53, sangat tidak mungkin nilai F ini terjadi secara kebetulan. (Dengan Alpha = 0,05, hipotesis bahwa tidak ada hubungan antara known_y dan known_x akan ditolak ketika F melebihi tingkat kritis, 4,53.) Anda bisa menggunakan fungsi FDIST di Excel untuk mendapatkan probabilitas bahwa nilai F tinggi ini terjadi secara kebetulan. Misalnya, FDIST(459,753674, 4, 6) = 1,37E-7, probabilitas yang sangat kecil. Anda bisa menyimpulkan, baik dengan menemukan tingkat kritis F dalam tabel atau dengan menggunakan fungsi FDIST , bahwa persamaan regresi berguna dalam memprediksi nilai gedung kantor yang dinilai di area ini. Ingatlah bahwa sangat penting untuk menggunakan nilai v1 dan v2 yang benar yang dihitung dalam paragraf sebelumnya.
Contoh 5 - Menghitung Statistik t
Uji hipotesis lainnya akan menentukan apakah setiap koefisien kemiringan berguna dalam memperkirakan nilai taksir sebuah gedung perkantoran Contoh 3. Misalnya, untuk menguji koefisien umur untuk signifikansi statistik, bagi -234.24 (koefisien kemiringan umur) dengan 13.268 (perkiraan kesalahan standar koefisien umur dalam sel A15). Berikut ini adalah nilai t yang diobservasi:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
Jika nilai mutlak t cukup tinggi, dapat disimpulkan bahwa koefisien kemiringan berguna dalam memperkirakan nilai taksir sebuah gedung perkantoran dalam Contoh 3. Tabel berikut ini menunjukkan nilai mutlak 4 nilai t yang diobservasi.
Jika Anda membaca tabel dalam manual statistik, Anda akan menemukan bahwa t kritis, dua ekor, dengan 6 derajat kebebasan dan Alpha = 0,05 adalah 2,447. Nilai kritis ini juga bisa dicari dengan menggunakan fungsi TINV dalam Excel. TINV(0,05.6) = 2,447. Karena nilai mutlak t (17,7) lebih besar daripada 2,447, maka umur adalah variabel yang penting ketika memperkirakan nilai taksir sebuah gedung perkantoran. Masing-masing variabel bebas lain dapat diuji signifikansi statistiknya dengan cara serupa. Berikut ini adalah nilai-nilai t yang diobservasi untuk masing-masing variabel bebas.
|
Variabel |
nilai t yang diobservasi |
|---|---|
|
Luas lantai |
5,1 |
|
Jumlah kantor |
31,3 |
|
Jumlah pintu masuk |
4,8 |
|
Umur |
17,7 |
Semua nilai ini punya nilai mutlak yang lebih besar dari 2,447; oleh karena itu, semua variabel yang digunakan dalam persamaan regresi berguna dalam meramalkan nilai taksir gedung perkantoran di area ini.









