
Στο Excel, μπορείτε να δημιουργήσετε μοντέλα δεδομένων που περιέχουν εκατομμύρια γραμμές και, στη συνέχεια, να εκτελέσετε ισχυρή ανάλυση δεδομένων σε αυτά τα μοντέλα. Τα μοντέλα δεδομένων μπορούν να δημιουργηθούν με ή χωρίς το πρόσθετο Power Pivot για την υποστήριξη οποιουδήποτε αριθμού Συγκεντρωτικών Πινάκων, γραφημάτων και απεικονίσεων Power View στο ίδιο βιβλίο εργασίας.
Παρόλο που μπορείτε εύκολα να δημιουργήσετε τεράστια μοντέλα δεδομένων στο Excel, υπάρχουν πολλοί λόγοι για να μην το κάνετε. Πρώτον, τα μεγάλα μοντέλα που περιέχουν πλήθος πινάκων και στηλών είναι overkill για τις περισσότερες αναλύσεις και κάνουν για μια δυσκίνητη λίστα πεδίων. Δεύτερον, τα μεγάλα μοντέλα χρησιμοποιούν πολύτιμη μνήμη, επηρεάζοντας αρνητικά άλλες εφαρμογές και αναφορές που χρησιμοποιούν τους ίδιους πόρους συστήματος. Τέλος, στο Microsoft 365, τόσο το SharePoint Online όσο και το Excel Web App περιορίζουν το μέγεθος ενός αρχείου Excel στα 10 MB. Για μοντέλα δεδομένων βιβλίου εργασίας που περιέχουν εκατομμύρια γραμμές, θα φτάσετε στο όριο των 10 MB αρκετά γρήγορα. Ανατρέξτε στο θέμα Προδιαγραφές και όρια μοντέλου δεδομένων.
Σε αυτό το άρθρο, θα μάθετε πώς μπορείτε να δημιουργήσετε ένα μοντέλο που είναι πιο εύχρηστο και χρησιμοποιεί λιγότερη μνήμη. Αν αφιερώσετε χρόνο για να μάθετε βέλτιστες πρακτικές στη σχεδίαση αποτελεσματικών μοντέλων, αυτό θα έχει ως εξής: οποιοδήποτε μοντέλο δημιουργείτε και χρησιμοποιείτε, είτε το προβάλλετε στο Excel, στο Microsoft 365 στο SharePoint Online, σε έναν Office Online Server ή στο SharePoint.
Εξετάστε το ενδεχόμενο να εκτελέσετε επίσης τη βελτιστοποίηση μεγέθους βιβλίου εργασίας. Αναλύει το βιβλίο εργασίας του Excel και, εάν είναι δυνατό, το συμπιέζει περαιτέρω. Κάντε λήψη του προγράμματος βελτιστοποίησης μεγέθους βιβλίου εργασίας.
Σε αυτό το άρθρο
Αναλογίες συμπίεσης και μηχανισμός ανάλυσης εσωτερικής μνήμης
Τα μοντέλα δεδομένων στο Excel χρησιμοποιούν τον μηχανισμό ανάλυσης μνήμης για την αποθήκευση δεδομένων στη μνήμη. Ο μηχανισμός εφαρμόζει ισχυρές τεχνικές συμπίεσης για να μειώσει τις απαιτήσεις αποθήκευσης, συρρικνώνοντας ένα σύνολο αποτελεσμάτων μέχρι να είναι ένα κλάσμα του αρχικού μεγέθους του.
Κατά μέσο όρο, μπορείτε να αναμένετε ότι ένα μοντέλο δεδομένων θα είναι 7 έως 10 φορές μικρότερο από τα ίδια δεδομένα στο σημείο προέλευσής του. Για παράδειγμα, εάν εισάγετε 7 MB δεδομένων από μια βάση δεδομένων SQL Server, το μοντέλο δεδομένων στο Excel θα μπορούσε εύκολα να είναι 1 MB ή λιγότερο. Ο βαθμός συμπίεσης που επιτυγχάνεται στην πραγματικότητα εξαρτάται κυρίως από τον αριθμό των μοναδικών τιμών σε κάθε στήλη. Όσο πιο μοναδικές τιμές απαιτούνται, τόσο περισσότερη μνήμη απαιτείται για την αποθήκευσή τους.
Γιατί μιλάμε για συμπίεση και μοναδικές τιμές; Επειδή η δημιουργία ενός αποτελεσματικού μοντέλου που ελαχιστοποιεί τη χρήση της μνήμης έχει να κάνει με τη μεγιστοποίηση της συμπίεσης και ο ευκολότερος τρόπος για να το κάνετε αυτό είναι να απαλλαγείτε από τις στήλες που δεν χρειάζεστε πραγματικά, ειδικά εάν αυτές οι στήλες περιλαμβάνουν μεγάλο αριθμό μοναδικών τιμών.
Σημείωση: Οι διαφορές στις απαιτήσεις χώρου αποθήκευσης για μεμονωμένες στήλες μπορεί να είναι τεράστιες. Σε ορισμένες περιπτώσεις, είναι καλύτερα να έχετε πολλές στήλες με χαμηλό αριθμό μοναδικών τιμών αντί για μία στήλη με υψηλό αριθμό μοναδικών τιμών. Η ενότητα για τις βελτιστοποιήσεις Datetime καλύπτει λεπτομερώς αυτή την τεχνική.
Τίποτα δεν ξεπερνά μια στήλη που δεν υπάρχει για χαμηλή χρήση μνήμης
Η στήλη με μεγαλύτερη απόδοση μνήμης είναι αυτή που δεν εισαγάγατε ποτέ. Εάν θέλετε να δημιουργήσετε ένα αποτελεσματικό μοντέλο, εξετάστε κάθε στήλη και αναρωτηθείτε εάν συμβάλλει στην ανάλυση που θέλετε να εκτελέσετε. Αν δεν εμφανίζεται ή δεν είστε βέβαιοι, αφήστε το έξω. Μπορείτε πάντα να προσθέσετε νέες στήλες αργότερα, εάν τις χρειάζεστε.
Δύο παραδείγματα στηλών που πρέπει πάντα να εξαιρούνται
Το πρώτο παράδειγμα σχετίζεται με δεδομένα που προέρχονται από μια αποθήκη δεδομένων. Σε μια αποθήκη δεδομένων, είναι συνηθισμένο να βρίσκετε τεχνουργήματα διεργασιών ETL που φορτώνουν και ανανεώνουν δεδομένα στην αποθήκη. Στήλες όπως "create date", "update date" και "ETL run" δημιουργούνται κατά τη φόρτωση των δεδομένων. Καμία από αυτές τις στήλες δεν είναι απαραίτητη στο μοντέλο και θα πρέπει να καταργηθεί κατά την εισαγωγή δεδομένων.
Το δεύτερο παράδειγμα περιλαμβάνει την παράλειψη της στήλης πρωτεύοντος κλειδιού κατά την εισαγωγή ενός πίνακα δεδομένων.
Πολλοί πίνακες, συμπεριλαμβανομένων των πινάκων δεδομένων, έχουν πρωτεύοντα κλειδιά. Για τους περισσότερους πίνακες, όπως αυτούς που περιέχουν δεδομένα πελατών, υπαλλήλων ή πωλήσεων, θα θέλετε το πρωτεύον κλειδί του πίνακα, ώστε να μπορείτε να το χρησιμοποιήσετε για να δημιουργήσετε σχέσεις στο μοντέλο.
Οι πίνακες γεγονότων είναι διαφορετικοί. Σε έναν πίνακα δεδομένων, το πρωτεύον κλειδί χρησιμοποιείται για τον μοναδικό προσδιορισμό κάθε γραμμής. Παρόλο που είναι απαραίτητο για σκοπούς κανονικοποίησης, είναι λιγότερο χρήσιμο σε ένα μοντέλο δεδομένων όπου θέλετε να χρησιμοποιούνται μόνο οι στήλες για ανάλυση ή για τη δημιουργία σχέσεων πινάκων. Για το λόγο αυτό, κατά την εισαγωγή από έναν πίνακα δεδομένων, μην συμπεριλάβετε το πρωτεύον κλειδί του. Τα πρωτεύοντα κλειδιά σε έναν πίνακα γεγονότων καταναλώνουν τεράστιες ποσότητες χώρου στο μοντέλο, αλλά δεν παρέχουν κανένα όφελος, καθώς δεν μπορούν να χρησιμοποιηθούν για τη δημιουργία σχέσεων.
Σημείωση: Στις αποθήκες δεδομένων και στις πολυδιάστατες βάσεις δεδομένων, οι μεγάλοι πίνακες που αποτελούνται κυρίως από αριθμητικά δεδομένα αναφέρονται συχνά ως "πίνακες γεγονότων". Οι πίνακες δεδομένων συνήθως περιλαμβάνουν δεδομένα επιχειρηματικών επιδόσεων ή συναλλαγών, όπως σημεία δεδομένων πωλήσεων και κόστους που συναθροίζονται και ευθυγραμμίζονται με εταιρικές μονάδες, προϊόντα, τμήματα αγοράς, γεωγραφικές περιοχές και ούτω καθεξής. Όλες οι στήλες σε έναν πίνακα δεδομένων που περιέχουν εταιρικά δεδομένα ή που μπορούν να χρησιμοποιηθούν για την παραπομπή δεδομένων που είναι αποθηκευμένα σε άλλους πίνακες θα πρέπει να συμπεριληφθούν στο μοντέλο για την υποστήριξη της ανάλυσης δεδομένων. Η στήλη που θέλετε να αποκλείσετε είναι η στήλη πρωτεύοντος κλειδιού του πίνακα δεδομένων, η οποία αποτελείται από μοναδικές τιμές που υπάρχουν μόνο στον πίνακα δεδομένων και πουθενά αλλού. Επειδή οι πίνακες δεδομένων είναι τόσο τεράστιοι, ορισμένα από τα μεγαλύτερα κέρδη στην αποτελεσματικότητα του μοντέλου προέρχονται από τον αποκλεισμό γραμμών ή στηλών από πίνακες γεγονότων.
Τρόπος εξαίρεσης περιττών στηλών
Τα αποτελεσματικά μοντέλα περιέχουν μόνο τις στήλες που θα χρειαστείτε στο βιβλίο εργασίας σας. Εάν θέλετε να ελέγξετε ποιες στήλες περιλαμβάνονται στο μοντέλο, θα πρέπει να χρησιμοποιήσετε τον Οδηγό εισαγωγής πίνακα στο πρόσθετο Power Pivot για να εισαγάγετε τα δεδομένα αντί για το παράθυρο διαλόγου "Εισαγωγή δεδομένων" στο Excel.
Όταν ξεκινάτε τον "Οδηγό εισαγωγής πίνακα", επιλέγετε τους πίνακες που θα εισαγάγετε.
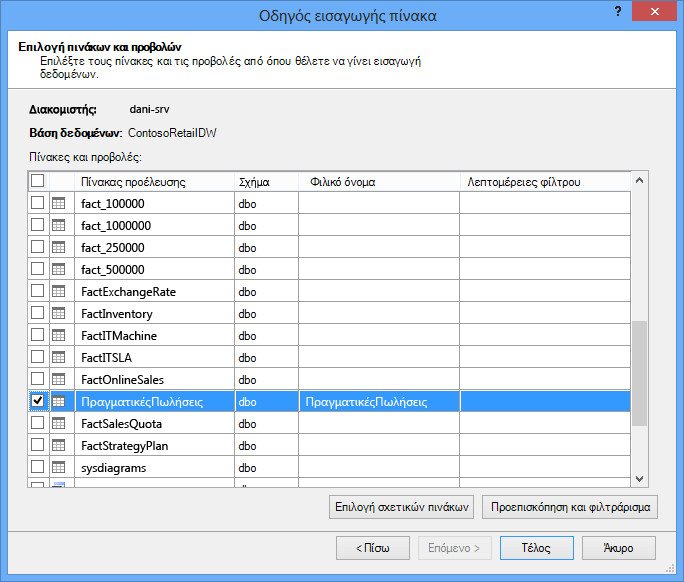
Για κάθε πίνακα, μπορείτε να κάνετε κλικ στο κουμπί Προεπισκόπηση & φίλτρο και να επιλέξετε τα τμήματα του πίνακα που πραγματικά χρειάζεστε. Συνιστάται να καταργήσετε πρώτα την επιλογή όλων των στηλών και, στη συνέχεια, να προχωρήσετε στον έλεγχο των στηλών που θέλετε, αφού εξετάσετε εάν απαιτούνται για την ανάλυση.
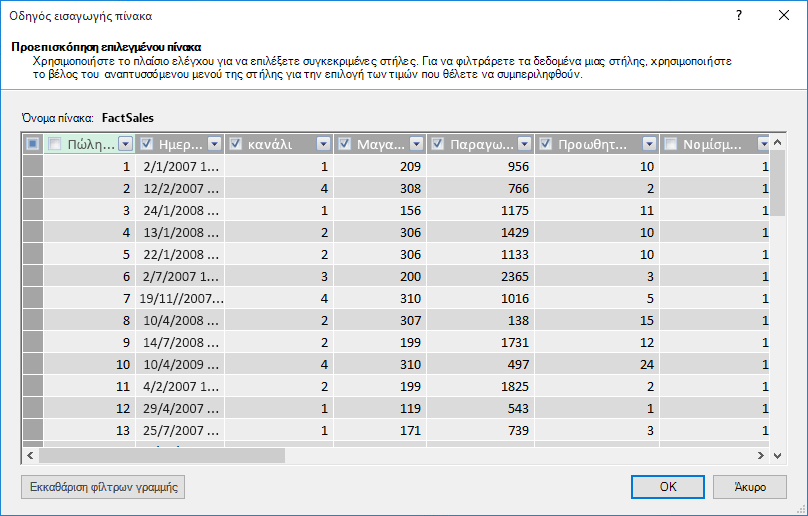
Τι γίνεται με το φιλτράρισμα μόνο των απαραίτητων γραμμών;
Πολλοί πίνακες σε εταιρικές βάσεις δεδομένων και αποθήκες δεδομένων περιέχουν ιστορικά δεδομένα που έχουν συσσωρευτεί για μεγάλα χρονικά διαστήματα. Επιπλέον, μπορεί να διαπιστώσετε ότι οι πίνακες που σας ενδιαφέρουν περιέχουν πληροφορίες για τομείς της επιχείρησης που δεν απαιτούνται για τη συγκεκριμένη ανάλυσή σας.
Χρησιμοποιώντας τον Οδηγό εισαγωγής πίνακα, μπορείτε να φιλτράρετε δεδομένα ιστορικού ή μη σχετικά δεδομένα και, επομένως, να εξοικονομήσετε πολύ χώρο στο μοντέλο. Στην παρακάτω εικόνα, ένα φίλτρο ημερομηνίας χρησιμοποιείται για την ανάκτηση μόνο γραμμών που περιέχουν δεδομένα για το τρέχον έτος, με εξαίρεση τα δεδομένα ιστορικού που δεν θα είναι απαραίτητα.
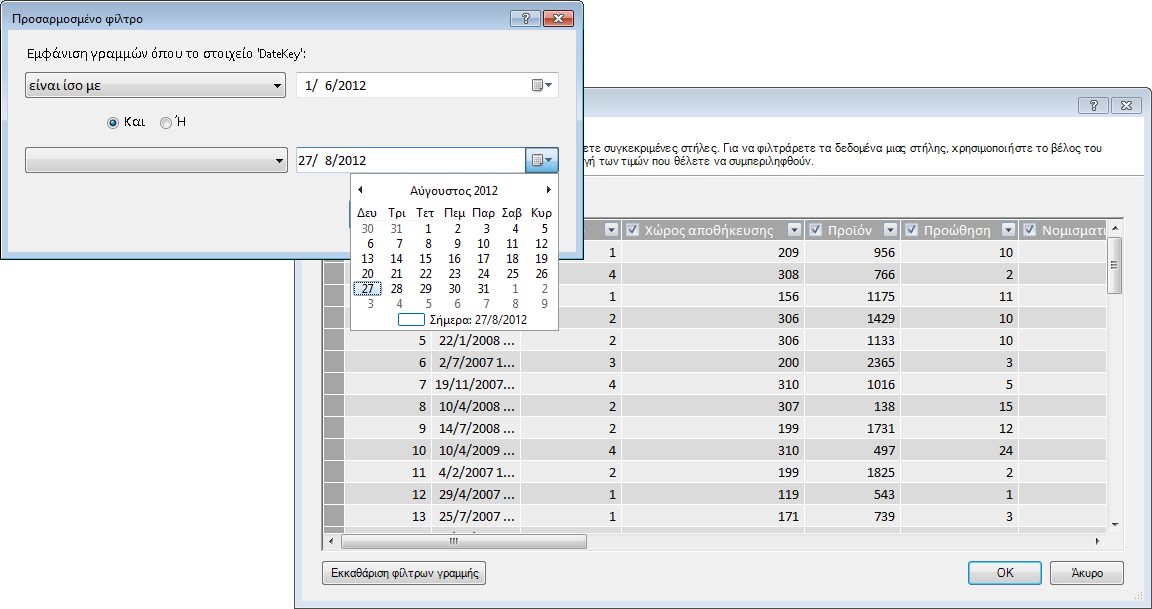
Τι γίνεται εάν χρειαζόμαστε τη στήλη; μπορούμε ακόμα να μειώσουμε το κόστος του χώρου;
Υπάρχουν μερικές πρόσθετες τεχνικές που μπορείτε να εφαρμόσετε για να κάνετε μια στήλη καλύτερη υποψήφια για συμπίεση. Να θυμάστε ότι το μόνο χαρακτηριστικό της στήλης που επηρεάζει τη συμπίεση είναι ο αριθμός των μοναδικών τιμών. Σε αυτή την ενότητα, θα μάθετε πώς μπορούν να τροποποιηθούν ορισμένες στήλες, ώστε να μειωθεί ο αριθμός των μοναδικών τιμών.
Τροποποίηση στηλών ημερομηνίας/ώρας
Σε πολλές περιπτώσεις, οι στήλες Datetime καταλαμβάνουν πολύ χώρο. Ευτυχώς, υπάρχουν πολλοί τρόποι για να μειώσετε τις απαιτήσεις χώρου αποθήκευσης για αυτόν τον τύπο δεδομένων. Οι τεχνικές θα διαφέρουν ανάλογα με τον τρόπο που χρησιμοποιείτε τη στήλη και το επίπεδο άνεσης στη δημιουργία ερωτημάτων SQL.
Οι στήλες ημερομηνίας και ώρας περιλαμβάνουν ένα τμήμα ημερομηνίας και μια ώρα. Όταν αναρωτηθείτε εάν χρειάζεστε μια στήλη, κάντε την ίδια ερώτηση πολλές φορές για μια στήλη Datetime:
-
Χρειάζομαι το μέρος του χρόνου;
-
Χρειάζομαι το τμήμα χρόνου στο επίπεδο των ωρών; πρακτικά? Δευτερόλεπτα? , χιλιοστά του δευτερολέπτου;
-
Έχω πολλές στήλες datetime επειδή θέλω να υπολογίσω τη διαφορά μεταξύ τους ή απλώς για να συγκεντρώσω τα δεδομένα κατά έτος, μήνα, τρίμηνο και ούτω καθεξής.
Ο τρόπος με τον οποίο μπορείτε να απαντήσετε σε κάθε μία από αυτές τις ερωτήσεις καθορίζει τις επιλογές σας για την αντιμετώπιση της στήλης Datetime.
Όλες αυτές οι λύσεις απαιτούν τροποποίηση ενός ερωτήματος SQL. Για να διευκολύνετε την τροποποίηση του ερωτήματος, θα πρέπει να φιλτράρετε τουλάχιστον μία στήλη σε κάθε πίνακα. Φιλτράροντας μια στήλη, αλλάζετε την κατασκευή ενός ερωτήματος από συντομογραφία (SELECT *) σε μια πρόταση SELECT που περιλαμβάνει πλήρως προσδιορισμένων ονομάτων στηλών, τα οποία είναι πολύ πιο εύκολο να τροποποιηθούν.
Ας ρίξουμε μια ματιά στα ερωτήματα που έχουν δημιουργηθεί για εσάς. Από το παράθυρο διαλόγου Ιδιότητες πίνακα, μπορείτε να μεταβείτε στο Πρόγραμμα επεξεργασίας ερωτήματος και να δείτε το τρέχον ερώτημα SQL για κάθε πίνακα.

Από τις Ιδιότητες πίνακα, επιλέξτε Πρόγραμμα επεξεργασίας ερωτήματος.
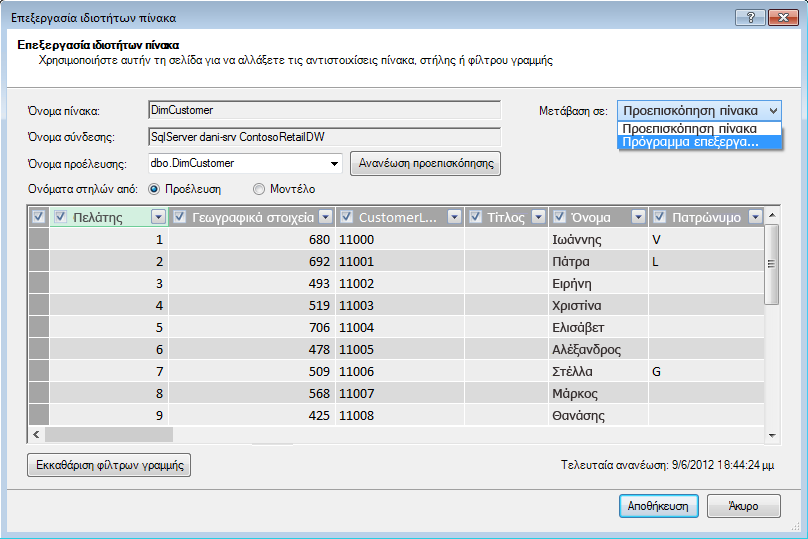
Το Πρόγραμμα επεξεργασίας ερωτήματος εμφανίζει το ερώτημα SQL που χρησιμοποιείται για τη συμπλήρωση του πίνακα. Εάν έχετε φιλτράρει οποιαδήποτε στήλη κατά την εισαγωγή, το ερώτημά σας περιλαμβάνει πλήρως προσδιορισμένα ονόματα στηλών:
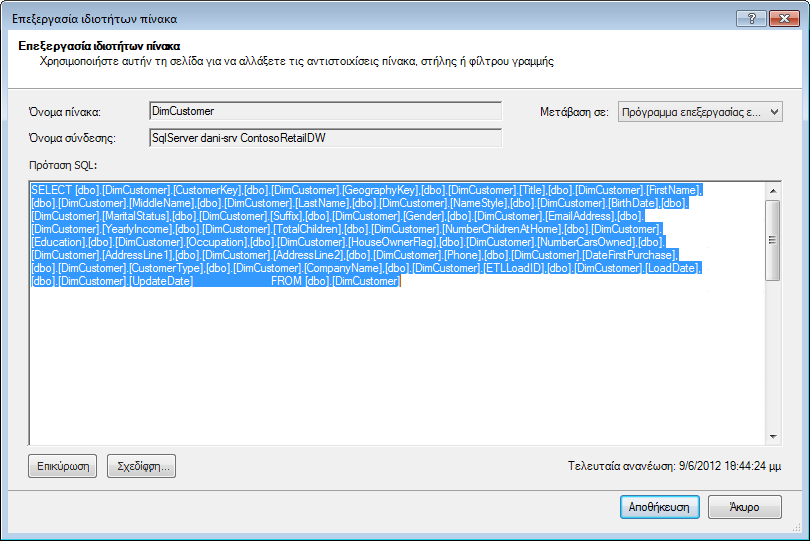
|
Αντίθετα, εάν έχετε εισαγάγει έναν πίνακα στο σύνολό του, χωρίς να καταργήσετε την επιλογή οποιασδήποτε στήλης ή να εφαρμόσετε οποιοδήποτε φίλτρο, θα δείτε το ερώτημα ως "Επιλογή * από", το οποίο θα είναι πιο δύσκολο να τροποποιηθεί:
|
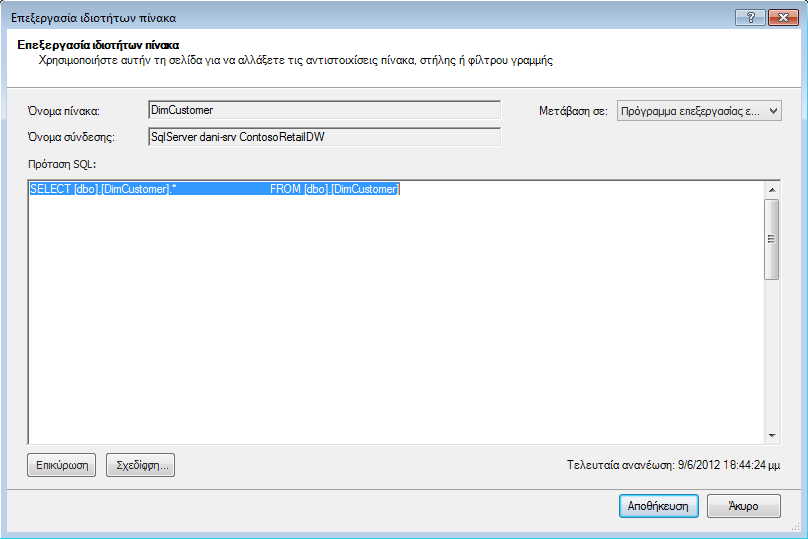
Τροποποίηση του ερωτήματος SQL
Τώρα που γνωρίζετε πώς μπορείτε να βρείτε το ερώτημα, μπορείτε να το τροποποιήσετε για να μειώσετε περαιτέρω το μέγεθος του μοντέλου σας.
-
Για στήλες που περιέχουν νομισματικές μονάδες ή δεκαδικά δεδομένα, εάν δεν χρειάζεστε τα δεκαδικά ψηφία, χρησιμοποιήστε αυτή τη σύνταξη για να καταργήσετε τα δεκαδικά ψηφία:
"SELECT ROUND([Decimal_column_name],0)... .”
Εάν χρειάζεστε τα σεντ αλλά όχι κλάσματα των λεπτών, αντικαταστήστε το 0 με το 2. Εάν χρησιμοποιείτε αρνητικούς αριθμούς, μπορείτε να τους στρογγυλοποιήσετε σε μονάδες, δεκάδες, εκατοντάδες κ.λπ.
-
Εάν έχετε μια στήλη Datetime με το όνομα dbo. Μεγαλόστομε. [Ημερομηνία ώρας] και δεν χρειάζεστε το Τμήμα ώρας, χρησιμοποιήστε τη σύνταξη για να απαλλαγείτε από την ώρα:
"SELECT CAST (dbo. Μεγαλόστομε. [Ημερομηνία ώρα] ως ημερομηνία) AS [Ημερομηνία ώρα]) "
-
Εάν έχετε μια στήλη Datetime με το όνομα dbo. Μεγαλόστομε. [Ημερομηνία/Ώρα] και χρειάζεστε και τα δύο τμήματα Ημερομηνία και Ώρα, χρησιμοποιήστε πολλές στήλες στο ερώτημα SQL αντί για τη μεμονωμένη στήλη Datetime:
"SELECT CAST (dbo. Μεγαλόστομε. [Ημερομηνία/Ώρα] ως ημερομηνία ) AS [Ημερομηνία/Ώρα],
datepart(hh, dbo. Μεγαλόστομε. [Ημερομηνία/Ώρα]) ως [Ώρες ημερομηνίας/ώρας],
datepart(mi, dbo. Μεγαλόστομε. [Ημερομηνία/Ώρα]) ως [Λεπτά ώρας ημερομηνίας],
datepart(ss; dbo. Μεγαλόστομε. [Ημερομηνία/Ώρα]) ως [Δευτερόλεπτα ημερομηνίας/ώρας],
datepart(ms, dbo. Μεγαλόστομε. [Ημερομηνία/Ώρα]) as [Χιλιοστά του δευτερολέπτου ημερομηνίας]"
Χρησιμοποιήστε όσες στήλες χρειάζεστε για να αποθηκεύσετε κάθε τμήμα σε ξεχωριστές στήλες.
-
Εάν χρειάζεστε ώρες και λεπτά και τα προτιμάτε μαζί ως μία στήλη χρόνου, μπορείτε να χρησιμοποιήσετε τη σύνταξη:
Timefromparts(datepart(hh, dbo. Μεγαλόστομε. [Ημερομηνία ώρα]), datepart(mm; dbo. Μεγαλόστομε. [Ημερομηνία/Ώρα])) as [Date Time HourMinute]
-
Εάν έχετε δύο στήλες ημερομηνίας/ώρας, όπως [Ώρα έναρξης] και [Ώρα λήξης], και αυτό που πραγματικά χρειάζεστε είναι η χρονική διαφορά μεταξύ τους σε δευτερόλεπτα ως στήλη που ονομάζεται [Διάρκεια], καταργήστε και τις δύο στήλες από τη λίστα και προσθέστε:
"datediff(ss;[Ημερομηνία έναρξης];[Ημερομηνία λήξης]) ως [Διάρκεια]"
Εάν χρησιμοποιήσετε τη λέξη-κλειδί ms αντί για ss, θα λάβετε τη διάρκεια σε χιλιοστά του δευτερολέπτου
Χρήση υπολογισμένων μετρήσεων DAX αντί για στήλες
Εάν έχετε εργαστεί στο παρελθόν με τη γλώσσα παράστασης DAX, ίσως γνωρίζετε ήδη ότι οι υπολογιζόμενες στήλες χρησιμοποιούνται για την εξαγωγή νέων στηλών με βάση κάποια άλλη στήλη στο μοντέλο, ενώ οι υπολογισμένες μετρήσεις ορίζονται μία φορά στο μοντέλο, αλλά υπολογίζονται μόνο όταν χρησιμοποιούνται σε Συγκεντρωτικό Πίνακα ή άλλη αναφορά.
Μια τεχνική εξοικονόμησης μνήμης είναι η αντικατάσταση των κανονικών ή υπολογιζόμενων στηλών με υπολογισμένες μετρήσεις. Το κλασικό παράδειγμα είναι η Τιμή μονάδας, η Ποσότητα και το Σύνολο. Εάν έχετε και τα τρία, μπορείτε να εξοικονομήσετε χώρο διατηρώντας μόνο δύο και υπολογίζοντας το τρίτο χρησιμοποιώντας DAX.
Ποιες 2 στήλες πρέπει να διατηρήσετε;
Στο παραπάνω παράδειγμα, διατηρήστε την Ποσότητα και την Τιμή μονάδας. Αυτές οι δύο τιμές έχουν λιγότερες τιμές από το σύνολο. Για να υπολογίσετε το σύνολο, προσθέστε μια υπολογισμένη μέτρηση ως εξής:
"Συνολικές πωλήσεις:=sumx('Πίνακας πωλήσεων';'Πίνακας πωλήσεων'[Τιμή μονάδας]*'Πίνακας πωλήσεων'[Ποσότητα])"
Οι υπολογιζόμενες στήλες είναι σαν κανονικές στήλες στο ότι και οι δύο καταλαμβάνουν χώρο στο μοντέλο. Αντίθετα, οι υπολογισμένες μετρήσεις υπολογίζονται στη στιγμή και δεν καταλαμβάνουν χώρο.
Συμπέρασμα
Σε αυτό το άρθρο, συζητήσαμε για διάφορες προσεγγίσεις που μπορούν να σας βοηθήσουν να δημιουργήσετε ένα μοντέλο με μεγαλύτερη αποτελεσματικότητα στη μνήμη. Ο τρόπος για να μειώσετε το μέγεθος αρχείου και τις απαιτήσεις μνήμης ενός μοντέλου δεδομένων είναι να μειώσετε τον συνολικό αριθμό στηλών και γραμμών και τον αριθμό των μοναδικών τιμών που εμφανίζονται σε κάθε στήλη. Ακολουθούν ορισμένες τεχνικές που καλύψαμε:
-
Η κατάργηση στηλών είναι φυσικά ο καλύτερος τρόπος για να εξοικονομήσετε χώρο. Αποφασίστε ποιες στήλες χρειάζεστε πραγματικά.
-
Μερικές φορές μπορείτε να καταργήσετε μια στήλη και να την αντικαταστήσετε με μια υπολογισμένη μέτρηση στον πίνακα.
-
Ενδέχεται να μην χρειάζεστε όλες τις γραμμές σε έναν πίνακα. Μπορείτε να φιλτράρετε γραμμές στον Οδηγό εισαγωγής πίνακα.
-
Γενικά, η διάσπαση μιας μεμονωμένης στήλης σε πολλά διακριτά τμήματα είναι ένας καλός τρόπος για να μειώσετε τον αριθμό των μοναδικών τιμών σε μια στήλη. Κάθε ένα από τα τμήματα θα έχει μικρό αριθμό μοναδικών τιμών και το συνδυασμένο σύνολο θα είναι μικρότερο από την αρχική ενοποιημένη στήλη.
-
Σε πολλές περιπτώσεις, χρειάζεστε επίσης τα διακριτά τμήματα για να χρησιμοποιήσετε ως αναλυτές στις αναφορές σας. Όταν χρειάζεται, μπορείτε να δημιουργήσετε ιεραρχίες από τμήματα όπως Ώρες, Λεπτά και Δευτερόλεπτα.
-
Πολλές φορές, οι στήλες περιέχουν περισσότερες πληροφορίες από όσες χρειάζεστε. Για παράδειγμα, ας υποθέσουμε ότι μια στήλη αποθηκεύει δεκαδικά ψηφία, αλλά έχετε εφαρμόσει μορφοποίηση για να αποκρύψετε όλα τα δεκαδικά ψηφία. Η στρογγυλοποίηση μπορεί να είναι πολύ αποτελεσματική στη μείωση του μεγέθους μιας αριθμητικής στήλης.
Τώρα που έχετε κάνει ό,τι μπορείτε για να μειώσετε το μέγεθος του βιβλίου εργασίας σας, εξετάστε το ενδεχόμενο να εκτελέσετε επίσης τη Βελτιστοποίηση μεγέθους βιβλίου εργασίας. Αναλύει το βιβλίο εργασίας του Excel και, εάν είναι δυνατό, το συμπιέζει περαιτέρω. Κάντε λήψη του προγράμματος βελτιστοποίησης μεγέθους βιβλίου εργασίας.
Σχετικές συνδέσεις
Προδιαγραφές και όρια μοντέλου δεδομένων
Βελτιστοποίηση μεγέθους βιβλίου εργασίας
PowerPivot: Ισχυρή ανάλυση δεδομένων και μοντελοποίηση δεδομένων στο Excel









